Published
- 21 min read
Frequently asked Splunk Interview Questions (2024) Part 1
Most commonly asked Splunk interview questions (Part 1/2).
Introduction
In a Splunk interview, candidates can expect questions about their experience with Splunk, data analysis, security, and troubleshooting. This blog post is part 1 of the Splunk Interview Questions series. Here are some sample questions that a candidate might encounter in a Splunk interview:
1. Splunk Basics:
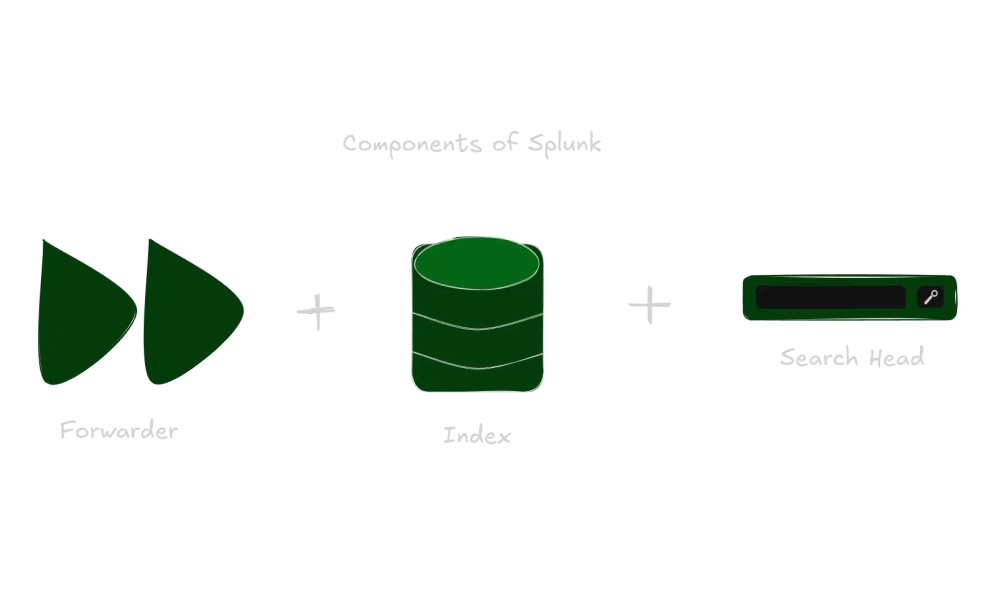
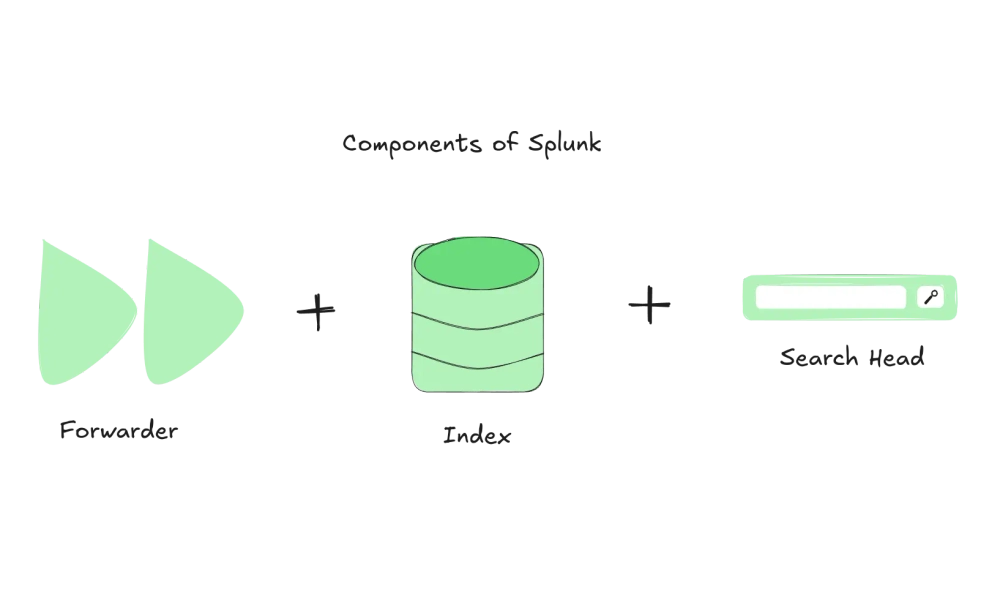
1.1 What is Splunk and what are its main components?
Splunk is a data analytics platform that helps organizations collect, index, search, and analyze machine-generated data from various sources. It provides real-time insights into operational and business performance, enhancing security and compliance. Known for its user-friendly web interface, Splunk is widely used for log management, operational intelligence, and real-time analytics, providing enhanced visibility into IT operations and business analytics.
Main Components of Splunk
- Splunk Forwarder:
- Universal Forwarder: The Universal Forwarder is a lightweight agent that collects logs, metrics, and events from various sources and forwards them to a Splunk indexer for analysis. It Has a small footprint, low resource usage, and minimal configuration requirements.
- Heavy Forwarder: The Heavy Forwarder, like the Universal Forwarder, offers additional features such as data parsing, filtering, and local indexing. It acts as a full-fledged agent with all the Universal Forwarder’s features, plus enhanced processing and analysis capabilities.
- Splunk Indexer:
- The core component that receives, indexes, and stores the data collected by the forwarders. It transforms raw data into searchable events and stores them in Splunk’s proprietary data store called the “index”. Indexers perform processing tasks such as parsing, de-duplication, and compression of the incoming data.
- Splunk Search Head:
- The user interface component that provides the web interface for users to search, analyze, and visualize the data indexed by Splunk. It handles user queries and generates reports, dashboards, and alerts based on the indexed data.
- Splunk Deployment Server:
- The Deployment Server is a centralized management tool that enables administrators to manage and distribute configurations, apps, and updates to multiple Splunk components in a distributed environment. It also provides role-based access control (RBAC) and other security features.
- Splunk Cluster Master:
- Manages data replication across multiple indexers in a Splunk cluster to ensure high availability and data redundancy. It coordinates data distribution and replication across the cluster.
- Index Cluster:
- An index cluster is a group of indexers that work together to provide high availability, scalability, and fault tolerance for data ingestion and search. It enables organizations to handle large volumes of data while ensuring reliability and performance.
- License Manager:
- A license manager is a component that manages the licensing of Splunk software, ensuring compliance with the terms of the agreement and providing usage metrics and reports to administrators.
- Splunk Apps and Add-ons:
- Pre-built applications and extensions that provide additional functionality and integrations for Splunk. These can include dashboards, reports, and data inputs tailored for specific use cases like security, IT operations, and business analytics.
1.2 How does Splunk index data, and what are the benefits of indexing?
Splunk indexes data through processes that transform raw machine data into searchable events. Here’s a high-level overview of how Splunk indexes data:
- Data Ingestion:
- Data Collection: Splunk collects data from various sources such as log files, network events, application data, and more. This data can be collected using Splunk forwarders or directly from the sources.
- Data Parsing: The indexer parses the incoming data into smaller units called “events” based on configurable rules such as timestamps, delimiters, and patterns. Each event is associated with source, source type, and host metadata.
- Data Processing:
- Timestamp Extraction: Splunk extracts timestamps from the events to enable time-based searches and analysis.
- Field Extraction: Splunk automatically extracts fields from the events, such as host, source, and source type. It uses regular expressions or predefined configurations to extract additional fields.
- De-duplication: The indexer removes duplicate events based on a hash value calculated from the event data and metadata. This operation reduces storage space and improves search performance.
- Compression: The indexer compresses the event data using a lossless compression algorithm such as LZ4 or Snappy to reduce disk space usage and improve search performance.
- Enrichment: The indexer enriches the event data with additional metadata such as hostname, IP address, and geolocation based on configurable lookup tables and external data sources. This operation enables users to perform more advanced searches and analytics on their data.
- Data Indexing:
- The indexer writes the event data and metadata to the index, a flat file system optimized for search and analysis. Each index has data structures, such as buckets, bloom filters, and summary indexes, that enable fast and efficient searching and filtering.
Benefits of Indexing in Splunk
- Scalability: Indexing enables organizations to handle large volumes of data while ensuring reliability and performance. The index can be distributed across multiple nodes or clusters to increase capacity and availability.
- Fast Searching: Indexing enables users to perform fast and efficient searches on their data, even when dealing with millions or billions of events. Splunk’s search language (SPL) provides powerful filtering, sorting, grouping, and aggregation capabilities that enable users to extract insights and patterns from their data.
- Data Retention: Indexing enables organizations to retain their data for a more extended period of time, which is essential for compliance, auditing, and trend analysis. Splunk’s index retention policies allow users to define how long they will keep their data based on configurable age, size, and type rules.
- Advanced Analytics: Indexing enables organizations to perform advanced analytics on their data, including machine learning, predictive modelling, and anomaly detection. Splunk’s Apps and Add-ons provide pre-built solutions for various industries and use cases that enable users to leverage the power of indexing for their specific needs.
- Data Security: Indexing enables organizations to secure their data using access controls, encryption, and auditing mechanisms. Splunk’s security features allow users to protect their data from unauthorized access, tampering, and deletion.
1.3 Can you explain the difference between raw data, events, and fields in Splunk?
Raw Data
- Definition: Raw data refers to the original, unprocessed data collected from various sources such as log files, network devices, applications, and sensors. It is the data in its native format before any processing or indexing by Splunk.
- Examples: Log entries from a web server, syslog messages from network devices, JSON data from APIs, CSV files, etc.
- Characteristics:
- Unstructured or semi-structured.
- Contains timestamps, messages, and other metadata.
- Can be in formats like plain text, JSON, XML, or CSV.
Events
- Definition: An event in Splunk is a searchable record representing a specific occurrence or data point. Events are created by parsing and segmenting raw data into individual units that Splunk can index and search.
- Creation: Splunk parses raw data into events based on line breaks, timestamps, or other delimiters. Each event typically corresponds to a single log entry or data point.
- Characteristics:
- Structured and indexed for search.
- Contains a timestamp that Splunk uses for time-based searches.
- Examples:
- A single log entry from a web server.
- A syslog message from a network device.
- A JSON object representing a user action.
Fields
- Definition: Fields are named values extracted from events during indexing. Each field represents specific information contained within an event, such as a timestamp, source IP address, or user agent string. Splunk uses field extraction rules (FERs) to identify and extract fields from raw data.
- Extraction: Splunk can automatically extract fields during indexing or manually define them using regular expressions, props.conf, or transforms.conf configurations.
- Types:
- Default Fields: Automatically extracted fields like
host,source,sourcetype, andtimestamp. - Automatic Field Extraction: Fields extracted based on predefined rules and patterns.
- Custom Fields: User-defined fields extracted using custom configurations.
- Default Fields: Automatically extracted fields like
- Examples:
host: The hostname or IP address of the device generating the data.source: The file or source from which the data was collected.sourcetype: The type of data source (e.g., access_combined for web server logs).status: The status code from a web server log.user: The username extracted from a log entry.
Relationship Between Raw Data, Events, and Fields
The main difference between these three concepts is their level of abstraction: raw data represents the lowest level of abstraction; events represent a slightly higher level of abstraction, and fields represent the highest level of abstraction.
For example, consider a log file that contains the following line:
2023-03-15 12:00:00 [INFO] User login successful: john.doe@example.comIn this case, the raw data is the entire line of text. When ingested into Splunk, this raw data is transformed into an event with a timestamp field (2023-03-15 12:00:00) and a message field (User login successful: john.doe@example.com). The event also contains other implicit fields such as the source IP address, hostname, and sourcetype.
By extracting fields from events, users can perform more advanced searches and gain deeper insights into their data. For example, they could use the fields command to filter search results based on specific field values or the stats command to calculate aggregate statistics based on a particular field.
2. Data Analysis:
2.1 How do you search for data in Splunk, and what are some common commands?
Searching for data in Splunk is a fundamental activity that allows you to query, analyze, and visualize your machine data. Splunk uses the Search Processing Language (SPL) to perform searches. To search for data in Splunk, users can follow these general steps:
- Open the Splunk search bar and enter the search query using SPL commands.
- Select the time range for the search by clicking on the time picker or entering a specific time range in the search bar.
- Run the search by clicking on the “Run” button or pressing Enter.
- View the search results, including raw events, charts, and tables.
- Refine the search query using additional SPL commands or filters.
Some common SPL commands used for searching data in Splunk are:
Basic Search Syntax
- Simple Search:
- Enter keywords or phrases in the search bar to perform a basic search.
- Example:
error- This search will return all events containing the word “error.”
- Searching for Specific Fields:
- You can search for specific fields using the field name and value.
- Example:
status=404- This search will return all events where the
statusfield is404.
- This search will return all events where the
- Combining Search Terms:
- You can combine search terms using Boolean operators like
AND,OR, andNOT.- Example:
error OR failure- This search will return events containing either “error” or “failure.”
- Example:
status=404 AND user=admin- This search will return events where the
statusis404and theuserisadmin.
- This search will return events where the
- Example:
|- This command is used to pipe the output of one command into another for further processing.- For example,
index=my_index | top sourcetypewill return the top source types in the my_index index.
- For example,
- You can combine search terms using Boolean operators like
Common SPL Commands
- stats:
- Used to perform statistical calculations on search results.
- Example:
index=web_logs | stats count by status- This command will return the events count for each
statusvalue in theweb_logsindex.
- This command will return the events count for each
- Example:
- Used to perform statistical calculations on search results.
- timechart:
- Used to create time-based charts.
- Example:
index=web_logs | timechart count by status- This command will create a time chart showing the events count for each
statusvalue over time.
- This command will create a time chart showing the events count for each
- Example:
- Used to create time-based charts.
- top:
- This command is used to return the top N values of a specified field or expression.
- Example:
index=web_logs | top user- This command will return the most common
uservalues in theweb_logsindex.
- This command will return the most common
- Example:
- This command is used to return the top N values of a specified field or expression.
- table:
- Used to format search results as a table.
- Example:
index=web_logs | table status, user, count- This command will return a table with the
status,user, andcountfields.
- This command will return a table with the
- Example:
- Used to format search results as a table.
- fields:
- This command allows you to choose which fields to include or exclude from the search results.
- Example:
index=my\_index | fields - _time - This command will return all fields except the time field.
- Example:
- This command allows you to choose which fields to include or exclude from the search results.
- sort:
- Used to sort search results.
- Example:
index=web_logs | stats count by user | sort - count- This command will return the events count for each
userand sort the results in descending order by count.
- This command will return the events count for each
- Example:
- Used to sort search results.
- search:
- Used to perform a sub-search, a search within a search.
- Example:
index=web_logs | search status=404- This command will return events from the
web_logsindex where thestatusis404.
- This command will return events from the
- Example:
- Used to perform a sub-search, a search within a search.
- eval:
- Used to create new fields or perform calculations.
- Example:
index=web_logs | eval response_time=end_time - start_time- This command will create a new field
response_timeby subtractingstart_timefromend_time.
- This command will create a new field
- Example:
- Used to create new fields or perform calculations.
- chart:
- Used to create charts based on search results.
- Example:
index=web_logs | chart count by status- This command will create a chart showing the events count for each
statusvalue.
- This command will create a chart showing the events count for each
- Example:
- Used to create charts based on search results.
- join:
- Used to join two sets of search results based on a common field.
- Example:
index=web_logs | join type=inner user [search index=user_logs]- This command will join the results of the
web_logsindex with the results of theuser_logsindex based on theuserfield.
- This command will join the results of the
- where:
- This command filters search results based on specific conditions.
- Example:
index=my_index | where status=200 - This command will return only those events with a status field equal to 200.
- Example:
- This command filters search results based on specific conditions.
- rename:
- This command renames fields in search results.
- For example,
index=my_index | rename source as hostwill rename the “source” field to “host”.
- For example,
- This command renames fields in search results.
- lookup:
- Used to enrich search results with data from a lookup table.
- Example:
index=web_logs | lookup user_details user OUTPUT user_email- This command will enrich the
web_logsindex results with theuser_emailfield from theuser_detailslookup table.
- This command will enrich the
- Example:
- Used to enrich search results with data from a lookup table.
- dedup:
- This command removes duplicate events from the search results.
- Example
index=my_index | dedup host - This command will return only one event for each unique value of the “host” field.
- Example
- This command removes duplicate events from the search results.
Advanced Search Techniques
- Using Wildcards:
- You can use wildcards to match patterns in your search.
- Example:
host=web*- This search will return events where the
hostfield starts with “web”.
- This search will return events where the
- Regular Expressions:
- You can use regular expressions to match patterns in your search.
- Example:
status=4\d\d- This search will return events where the
statusfield matches the 4XX pattern.
- This search will return events where the
- Time-Based Searches:
- You can specify a time range for your search.
- Example:
index=web_logs earliest=-24h- This search will return events from the
web_logsindex for the last 24 hours.
- This search will return events from the
2.2 Can you describe a complex search or report you created using Splunk?
Example1: Analyzing Web Server Logs for Performance Metrics
Objective:
Analyze web server logs to identify performance metrics such as response times, error rates, and the most frequently accessed URLs.
Steps:
- Data Ingestion:
- Ensure that you ingest web server logs into Splunk. You can ingest data using the Splunk forwarder or directly uploading log files.
- Basic Search:
- Start with a basic search to retrieve all web server log events.
index=web_logs
- Field Extraction:
- Extract relevant fields such as
status,response_time,clientip, anduri. index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)" | rex field=log_line "clientip=(\S+)" | rex field=log_line "uri=(\S+)"
- Extract relevant fields such as
- Filtering and Aggregation:
- Filter out unwanted events and aggregate data to calculate performance metrics.
index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)" | rex field=log_line "clientip=(\S+)" | rex field=log_line "uri=(\S+)" | where status!=200 | stats avg(response_time) as avg_response_time, count by uri
- Visualization:
- Create a time chart to visualize response times over time.
index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)" | rex field=log_line "clientip=(\S+)" | rex field=log_line "uri=(\S+)" | timechart avg(response_time) by uri
- Creating a Report:
- Save the search and schedule the report to run at regular intervals.
index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)" | rex field=log_line "clientip=(\S+)" | rex field=log_line "uri=(\S+)" | stats avg(response_time) as avg_response_time, count by uri | sort - count
- Scheduling the Report:
- Schedule the report to run daily and send the results via email.
index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)" | rex field=log_line "clientip=(\S+)" | rex field=log_line "uri=(\S+)" | stats avg(response_time) as avg_response_time, count by uri | sort - count | schedule daily
- Dashboard Integration:
- Add the report to a dashboard for real-time monitoring.
index=web_logs | rex field=log_line "response_time=(\d+)" | rex field=log_line "status=(\d+)"
Example2: Analyzing Web Server Logs for Errors
Objective:
Identify the top 10 source IP addresses that are generating errors in web server logs over the past week and displaying their associated hostnames and the total number of error messages for each IP address.
Steps:
index=web_logs sourcetype=access*This command specifies the source data to search (web server logs with a specific sourcetype).| rex field=_raw "(\S+) (\S+)This regular expression extracts the source IP address and hostname from the web log entries.| where status>=500This condition filters the search results to only include error messages (HTTP status codes 500 or higher).| bin span=1d _time firstThis time-based function groups the search results into one-day intervals, starting from the earliest event timestamp.| stats count by src_ipThis statistical function calculates the number of error messages for each unique source IP address within each time interval.| sort -countThis command sorts the search results in descending order based on the “count” field (i.e., the total number of error messages).| head 10This command limits the search results to the top 10 source IP addresses with the most error messages.| join src_ip [search index=dns_logs sourcetype=dns* | rex field=_raw "(\S+)This join operation combines data from the web logs and DNS logs, using the source IP address as the common key.[search index=dns_logs sourcetype=dns* | rex field=_raw "(\S+) (\S+)This nested search extracts the hostname associated with each source IP address from the DNS logs.| table src_ip, hostname, countThis command displays the final search results in a tabular format, including the top 10 source IP addresses, their associated hostnames, and the total number of error messages for each IP address.
2.3 How do you handle large volumes of data in Splunk, and what techniques do you use to optimize performance?
- Data Modeling: Creating data models can help optimize how data is stored and searched in Splunk. Data models define the hierarchical relationships between different data objects, allowing users to create accelerated summaries and pivot tables based on specific fields and attributes. By pre-aggregating and indexing data at the source, data models can significantly reduce search times and improve overall performance.
- Indexing Strategy: A well-designed indexing strategy is critical for handling large volumes of data in Splunk. Indexing involves partitioning data into smaller indexes based on specific criteria, such as time range, event type, or source. Index partitions can improve search times and reduce resource utilization by reducing the amount of data that needs to be searched and analyzed.
- Data Tiering:
- Hot, Warm, Cold, and Frozen: Use data tiering to store data based on its age and access frequency. Store hot data in fast, expensive storage, and archive cold data in slower, cheaper storage.
- Index Archiving: Archive old data to reduce the index size and improve search performance.
- Data Compression: Splunk supports several compression algorithms that can help reduce the size of indexed data, including LZ4, Snappy, and Gzip. Users can significantly reduce storage requirements and improve search performance by compressing data before it is indexed.
- Search Optimization:
Several techniques for optimizing searches in Splunk include using the
transactioncommand to group events into transactions or thestatscommand to perform aggregations on large data sets. Users can also use summary indexing and roll-up strategies to precompute and cache aggregate data, reducing search times and improving performance.- Efficient Queries:
- Use Filters Early: Apply filters early in your search queries to reduce the amount of data processed.
- Avoid Wildcards: Minimize using wildcards and regular expressions, as they can be resource-intensive.
- Use Accelerated Data Models: Create and use accelerated data models for frequently run searches to speed up query performance.
- Summary Indexing:
- Create Summary Indexes: Use summary indexing to create smaller, summarized datasets for frequently run searches. Summary indexing reduces the volume of data that needs processing for these searches.
- Data Model Acceleration: Accelerate data models to improve the performance of searches that use these models.
- Search Job Management:
- Real-Time Searches: Use real-time searches for monitoring and alerting to minimize the impact on system resources.
- Scheduled Searches: Schedule heavy searches during off-peak hours to distribute the load evenly.
- Efficient Queries:
- Resource Management:
Managing system resources is critical for handling large volumes of data in Splunk. Resource management includes monitoring CPU, memory, and disk usage and adjusting settings such as the number of search heads, indexers, and forwarders based on workload demands. Users can also use load balancing and clustering techniques to distribute workloads across multiple nodes and improve overall performance.
- Monitoring vs. API: Use monitoring inputs (e.g., monitoring files or directories) for large, continuously generated data. Use API-based inputs like HTTP Event Collector (HEC) for structured data.
- Batching: Configure inputs to batch data before sending it to Splunk to reduce network overhead.
- Data Retention and Archiving: Managing data retention policies is essential for maintaining efficient indexing and search performance in Splunk. Data retention involves archiving or deleting old data that is no longer needed based on specific criteria such as time range or event type. Users can also use external storage solutions, such as cold storage or object stores, to offload infrequently accessed data and reduce storage costs.
- Monitoring and Alerting: Monitoring system performance and setting up alerts for potential issues is critical for ensuring optimal search and indexing performance in Splunk. Users can use built-in monitoring tools like the Splunk Performance Manager and the Splunk App for Infrastructure to track resource utilization and identify potential bottlenecks or errors.
3. Security:
3.1 How do you configure Splunk for security and compliance requirements?
1. Access Control and Authentication
Implementing access controls is critical for securing Splunk and protecting sensitive data. Access controls include setting up firewalls, network segmentation, and VPN connections to restrict access to the Splunk environment.
- Role-Based Access Control (RBAC):
- Define roles and permissions to control access to Splunk data and features. Assign roles to users based on their job functions and the principle of least privilege.
- Example roles include admin, power user, user, and can_delete.
- Authentication:
- Integrate Splunk with external authentication systems such as LDAP, Active Directory, or SAML for centralized user management and single sign-on (SSO).
- Enable multi-factor authentication (MFA) to add an extra layer of security.
2. Data Protection
- Encryption:
- Enable encryption for data in transit using TLS/SSL, IPsec, or AES-256 to secure communications between Splunk components and clients.
- Encrypt data at rest using Splunk’s built-in encryption features or external encryption solutions.
- Use external key management solutions like AWS KMS or Azure Key Vault to manage encryption keys and ensure secure data access.
- Data Masking:
- Use data masking to obfuscate sensitive information in search results and dashboards. Data masking avoids exposing sensitive data to unauthorized users.
3. Audit and Monitoring
- Audit Logs:
- Enable and configure audit logging to track user activities, system changes, and access to data. Regularly review audit logs to detect and investigate suspicious activities.
- Monitoring:
- Use Splunk’s monitoring capabilities to monitor security events, system logs, and compliance-related data continuously. Set up alerts and reports to notify administrators of potential security incidents or compliance violations.
4. Compliance Reporting
- Compliance Apps:
- Utilize Splunk apps and add-ons designed for specific compliance requirements, such as GDPR, HIPAA, PCI DSS, and SOX. These apps provide pre-built dashboards, reports, and alerts to help meet regulatory requirements.
- Custom Reports:
- Create custom reports and dashboards to track and demonstrate compliance with internal policies and external regulations. Schedule these reports to run at regular intervals and share them with stakeholders.
5. Data Retention and Archiving
- Data Retention Policies:
- Define and implement data retention policies to ensure that data is retained for the required period to meet compliance requirements. Use Splunk’s data retention settings to archive or delete old data automatically.
- Data Archiving:
- Archive old data to secondary or cold storage to reduce costs and maintain compliance with data retention policies. Ensure that archived data can be retrieved if needed for audits or investigations.
6. Incident Response
- Incident Response Plan:
- Develop and maintain an incident response plan that outlines the steps to take in case of a security incident or compliance violation. Use Splunk’s incident review and investigation capabilities to analyze and respond to incidents.
- Alerts and Notifications:
- Set up real-time alerts and notifications to promptly detect and respond to security incidents. Configure alerts to notify the appropriate teams via email, SMS, or integration with incident management systems.
- Security Testing:
- Performing regular security testing and vulnerability assessments is critical for ensuring the integrity and confidentiality of sensitive data. Security testing involves using tools like Splunk’s Security Information and Event Management (SIEM) solution or third-party security scanners to identify potential threats or vulnerabilities. Users can also automate incident response and threat-hunting processes using Splunk’s Phantom App.
7. Regular Updates and Patching
- Software Updates:
- Keep Splunk software up-to-date with the latest patches and updates to benefit from security enhancements and new features. Regularly review and apply updates to all Splunk components.
- Vulnerability Management:
- Implement a vulnerability management program to identify and mitigate security vulnerabilities in Splunk and related systems. Regularly scan for vulnerabilities and apply patches as needed.
8. Training and Awareness
- User Training:
- Provide regular training and awareness programs for users and administrators to ensure they understand and follow security and compliance policies—train users on best practices for using Splunk securely.
- Documentation:
- Maintain comprehensive documentation of security and compliance configurations, policies, and procedures. Regularly review and update documentation to reflect changes and improvements.
3.2 Can you explain how to create and manage roles, users, and access controls in Splunk?
1. Accessing the Splunk Web Interface
- Log In: Open a web browser and navigate to the URL of your Splunk instance. Log in with administrative credentials.
2. Managing Roles
- Access the Role Management Page:
- Click on the Settings option in the top navigation bar.
- Under the Access controls section, click on Roles.
- Create a New Role:
- Click on New Role.
- Enter a name for the role and, optionally, a description.
- Assign capabilities to the role by selecting the appropriate permissions. Capabilities define what actions a user with this role can perform.
- Click Save to create the role.
- Modify an Existing Role:
- Select the role you want to modify from the list.
- Adjust the capabilities as needed and click Save.
3. Managing Users
- Access the User Management Page:
- Click on the Settings option in the top navigation bar.
- Under the Access controls section, click on Users.
- Create a New User:
- Click on New User.
- Enter the username, full name, and email address.
- Assign the user to one or more roles by selecting the appropriate roles from the list.
- Click Save to create the user.
- Modify an Existing User:
- Select the user you want to modify from the list.
- Update the user information and roles as needed.
- Click Save to apply the changes.
4. Configuring Authentication Methods
- Access the Authentication Method Settings:
- Click on the Settings option in the top navigation bar.
- Under the Access controls section, click on Authentication method.
- Select Authentication Method:
- Choose the desired authentication method (e.g., LDAP, SAML, or Native Authentication).
- Configure the settings as required for the selected authentication method.
5. Assigning Permissions to Apps
- Access Asset Permissions:
- From the Home menu, select Administration.
- Select User Management > Asset Permissions.
- Configure Permissions:
- Select the user or group and assign the necessary permissions for specific apps.
- Enable granular asset access control to ensure that only authorized users have access to the apps.
6. Best Practices for Role-Based Access Control (RBAC)
- Principle of Least Privilege: Assign the minimum necessary permissions to users to perform their tasks.
- Regular Audits: Regularly review and audit user roles and permissions to ensure compliance and security.
- Use Groups: Assign roles to groups rather than individual users to simplify management and ensure consistency.