Published
- 26 min read
Frequently asked PySpark Interview Questions (2024)
Most commonly asked interview questions on PySpark.
Introduction
As you explore the most commonly asked interview questions on PySpark, remember that these are the questions you must be prepared to answer. Anticipate the possibility that the interviewer may initiate in-depth discussions on specific topics, aiming to gauge your depth of knowledge and understanding. By being prepared for such scenarios, you can approach your interview with confidence and readiness.
This guide serves as an entry point for your interview preparation on PySpark.
What is Spark?
Spark is an open-source distributed computing framework for large-scale data processing that provides in-memory caching, fault tolerance, and parallel processing capabilities. It can handle batch and real-time data processing efficiently. It integrates well with big data tools like Hadoop, Hive, and Kafka.
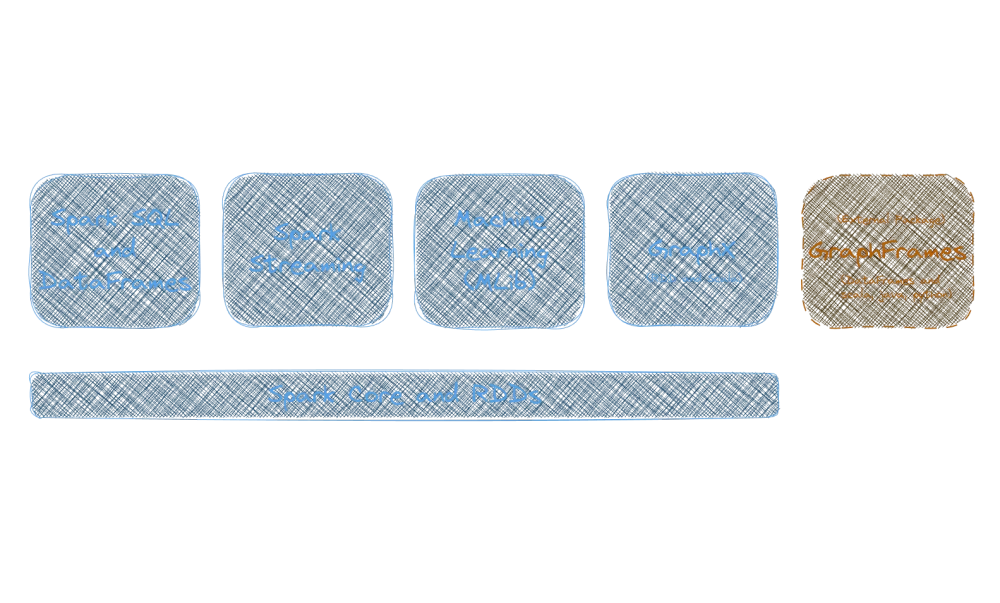
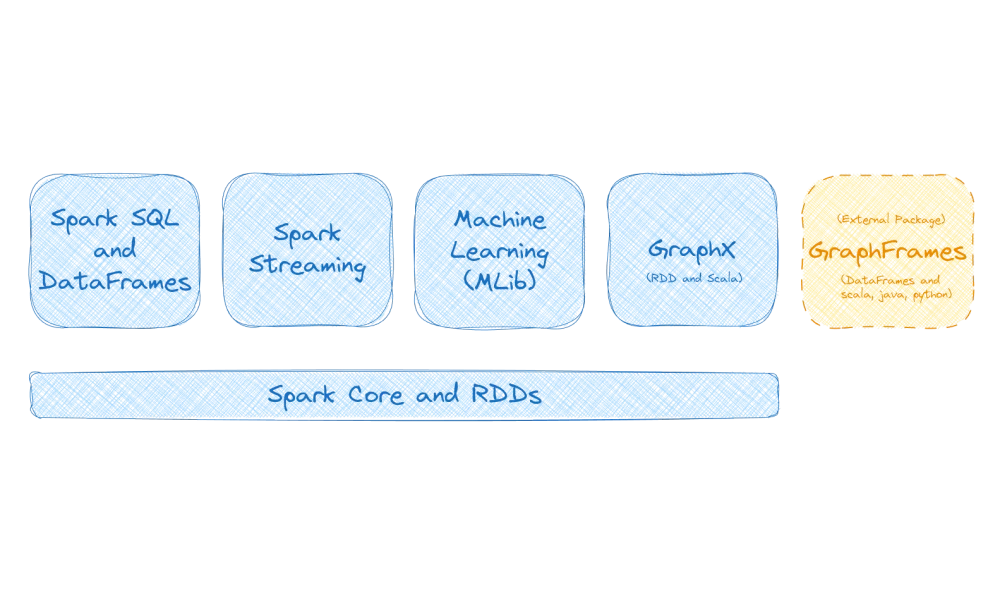
What are the core components of Spark?
Spark’s core components include:
- Spark Core: The base engine for executing distributed computations.
- Spark SQL: A module that provides a DataFrame-based API for structured data processing.
- Spark Streaming: A module for real-time data processing.
- MLlib: A library for machine learning and statistical analysis.
- GraphX: A library for graph processing. Supports only RDDs and Scala.
A handy external package that is not part of Spark Core:
- GraphFrames: GraphFrames for Apache Spark offers data-frame-based graphs and high-level APIs in Scala, Java, and Python, with extended functionality using Spark DataFrames.
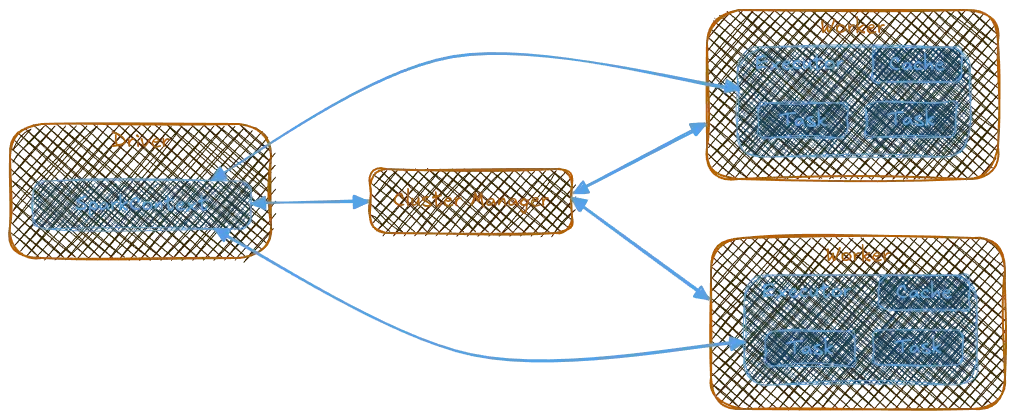
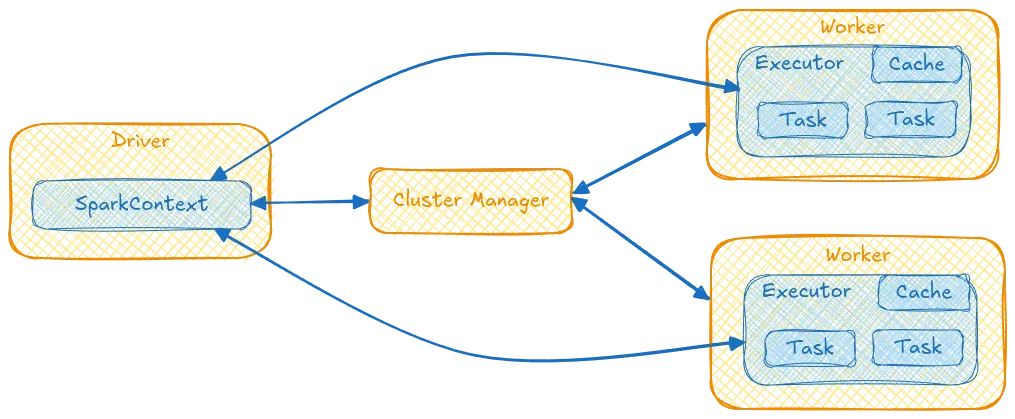
What is the difference between a Spark driver program and executors?
The Spark driver program runs on a single machine and manages the execution of Spark jobs by creating a SparkContext object. This object allocates resources and schedules tasks across worker nodes. Executors, on the other hand, are responsible for running individual tasks in parallel on different nodes in the cluster.
What is PySpark, and what are its benefits?
PySpark is a Python API for Spark, a distributed computing framework for large-scale data processing. PySpark provides a user-friendly Python interface to Spark’s core functionalities, such as RDDs (Resilient Distributed Datasets), DataFrames, and SQL queries. Some benefits of using PySpark include:
- Simplified syntax and more readable code compared to Scala or Java.
- Integration with popular Python data science libraries like Pandas, NumPy, and Matplotlib.
- Ability to leverage Spark’s distributed computing capabilities for large-scale data processing.
How does PySpark handle failures and fault tolerance?
PySpark provides fault tolerance through RDD lineage graphs, which allow it to recreate lost data partitions by re-executing the transformations that created them. Spark also uses a technique called “speculative execution” to improve fault tolerance by executing multiple copies of slow-running tasks and using the fastest one.
What is SparkContext?
Before Spark 2.0, SparkContext was the main entry point for Spark functionality. It was used to initialize and configure a Spark application. However, with the introduction of SparkSession, SparkContext is now primarily used internally by SparkSession.
Key Features of SparkContext
- RDD API:
SparkContextprovides methods to create and manipulate Resilient Distributed Datasets (RDDs), which are the fundamental data structure in Spark. - Configuration Management: Like SparkSession, you can configure various Spark properties through the
SparkContext. - Low-Level API:
SparkContextoffers lower-level APIs thanSparkSession, making it more suitable for advanced use cases.
Creating a SparkContext
Creating a SparkContext is less common in modern Spark applications, but it can still be done as follows:
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("My Spark Application").setMaster("local")
sc = SparkContext(conf=conf)What is SparkSession
The SparkSession is the main entry point for Spark functionality. It was introduced in Spark 2.0 to replace the older SparkContext, SQLContext, and HiveContext. The SparkSession provides a unified interface for interacting with various Spark APIs, including DataFrame, Dataset, SQL, and streaming.
Key Features of SparkSession
- Unified Entry Point:
SparkSessionconsolidates the functionality ofSparkContext,SQLContext, andHiveContext, making it easier to work with different Spark APIs. - DataFrame and Dataset API: It provides a way to create and manipulate DataFrames and Datasets, which are distributed collections of data organized into named columns.
- SQL Support:
SparkSessionallows you to execute SQL queries on DataFrames and Datasets. - Configuration Management: You can configure various Spark properties through the
SparkSession. - Streaming: It supports structured streaming, which allows you to process real-time data streams.
Creating a SparkSession
To create a SparkSession, you typically use the SparkSession.builder() method. Here is an example:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("My Spark Application") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()SparkContext vs SparkSession
- SparkSession: This is the modern entry point for Spark applications, providing a unified interface for DataFrame, Dataset, SQL, and streaming APIs.
- SparkContext: This is the older entry point, primarily used for RDD operations and lower-level APIs. It is now mostly used internally by
SparkSession.
In most cases, you should use SparkSession for new Spark applications, as it provides a more integrated and convenient interface for working with Spark’s various features.
What is PySpark’s lazy evaluation feature? How does it work?
PySpark uses a technique called “lazy evaluation” to optimize performance by delaying the execution of transformations until they are needed for action operations such as count(), show(), or collect(). When an action operation is triggered, PySpark constructs a directed acyclic graph (DAG) of transformations and then optimizes it using a “Catalyst” technique to generate efficient query plans.
For example, the code below doesn’t print the data to the console since no action has been performed on the RDD.
from pyspark.context import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2, 3, 4, 5], 5)
print(rdd)/CodeVxDev
pyspark
spark-submit rdd.py
11:9:15
ParallelCollectionRDD[0] at readRDDFromFile at PythonRDD.scala:289
But if we perform a collect operation on the RDD the list is printed to the console.
from pyspark.context import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2, 3, 4, 5], 5)
print(rdd.glom().collect())/CodeVxDev
pyspark
spark-submit rdd.py
11:9:15
24/08/25 13:55:19 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1585 24/08/25 13:55:19 INFO DAGScheduler: Submitting 5 missing tasks from ResultStage 0 (PythonRDD[1] at collect at /opt/spark/work-dir/src/rdd.py:5) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4)) 24/08/25 13:55:19 INFO TaskSchedulerImpl: Adding task set 0.0 with 5 tasks resource profile 0 24/08/25 13:55:19 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0) (fdbcb30000d4, executor driver, partition 0, PROCESS_LOCAL, 7622 bytes) 24/08/25 13:55:19 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1) (fdbcb30000d4, executor driver, partition 1, PROCESS_LOCAL, 7622 bytes) 24/08/25 13:55:19 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2) (fdbcb30000d4, executor driver, partition 2, PROCESS_LOCAL, 7622 bytes) 24/08/25 13:55:19 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3) (fdbcb30000d4, executor driver, partition 3, PROCESS_LOCAL, 7622 bytes) 24/08/25 13:55:19 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4) (fdbcb30000d4, executor driver, partition 4, PROCESS_LOCAL, 7622 bytes) 24/08/25 13:55:19 INFO Executor: Running task 3.0 in stage 0.0 (TID 3) 24/08/25 13:55:19 INFO Executor: Running task 2.0 in stage 0.0 (TID 2) 24/08/25 13:55:19 INFO Executor: Running task 4.0 in stage 0.0 (TID 4) 24/08/25 13:55:19 INFO Executor: Running task 0.0 in stage 0.0 (TID 0) 24/08/25 13:55:19 INFO Executor: Running task 1.0 in stage 0.0 (TID 1) 24/08/25 13:55:19 INFO PythonRunner: Times: total = 365, boot = 316, init = 48, finish = 1 24/08/25 13:55:19 INFO PythonRunner: Times: total = 365, boot = 320, init = 45, finish = 0 24/08/25 13:55:19 INFO PythonRunner: Times: total = 367, boot = 324, init = 42, finish = 1 24/08/25 13:55:19 INFO PythonRunner: Times: total = 371, boot = 328, init = 42, finish = 1 24/08/25 13:55:19 INFO PythonRunner: Times: total = 375, boot = 332, init = 42, finish = 1 24/08/25 13:55:19 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1369 bytes result sent to driver 24/08/25 13:55:19 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 1369 bytes result sent to driver 24/08/25 13:55:19 INFO Executor: Finished task 3.0 in stage 0.0 (TID 3). 1369 bytes result sent to driver 24/08/25 13:55:19 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1369 bytes result sent to driver 24/08/25 13:55:19 INFO Executor: Finished task 4.0 in stage 0.0 (TID 4). 1369 bytes result sent to driver 24/08/25 13:55:19 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 472 ms on fdbcb30000d4 (executor driver) (1/5) 24/08/25 13:55:19 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 487 ms on fdbcb30000d4 (executor driver) (2/5) 24/08/25 13:55:19 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 472 ms on fdbcb30000d4 (executor driver) (3/5) 24/08/25 13:55:19 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 473 ms on fdbcb30000d4 (executor driver) (4/5) 24/08/25 13:55:19 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 472 ms on fdbcb30000d4 (executor driver) (5/5) 24/08/25 13:55:19 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 24/08/25 13:55:19 INFO PythonAccumulatorV2: Connected to AccumulatorServer at host: 127.0.0.1 port: 59435 24/08/25 13:55:19 INFO DAGScheduler: ResultStage 0 (collect at /opt/spark/work-dir/src/rdd.py:5) finished in 0.614 s 24/08/25 13:55:19 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job 24/08/25 13:55:19 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished 24/08/25 13:55:19 INFO DAGScheduler: Job 0 finished: collect at /opt/spark/work-dir/src/rdd.py:5, took 0.642497 s [[1], [2], [3], [4], [5]]
What is the difference between RDD, DataFrame, and DataSet?
RDD (Resilient Distributed Dataset) is a fundamental data structure in Spark that represents an immutable distributed collection of objects partitioned across a cluster of machines. Each dataset in RDD is divided into logical partitions, which may be computed on different nodes of the cluster. It is fault-tolerant and provides strong consistency guarantees through lineage graphs.
from pyspark.context import SparkContext
sc = SparkContext()
rdd = sc.parallelize([1, 2, 3, 4, 5], 5)
print(rdd.glom().collect()) /CodeVxDev
pyspark
spark-submit rdd.py
11:9:15
[[1],[2],[3],[4],[5]]
DataFrame is a distributed collection of data organized into named columns. It is conceptually equivalent to a table in a relational database. DataFrames provide more optimized execution plans compared to RDDs, thanks to Spark’s Catalyst optimizer.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
)
df.show()/CodeVxDev
pyspark
spark-submit rdddataframe.py
11:9:15
+----+----------+--------+ |cost| date| expense| +----+----------+--------+ | 100|2024-08-09| meal| | 200|2024-08-10| travel| | 300|2024-08-11|training| | 400|2024-08-12| books| +----+----------+--------+
DataSet is a typed subset of DataFrame that provides more robust type safety and improved performance through compile-time type checking. It was introduced in Spark 1.6 for use cases that require more strict typing and better performance. The Dataset API is not available in Python; however, as Python is dynamic in nature, many of the benefits of DataSet API are readily available. For example, we can access the column of the DataFrame directly via cloumnName, as mentioned in the below code snippet.
df_expense = df[df.expense]
df_expense.show() /CodeVxDev
pyspark
spark-submit rdddataframe.py
11:9:15
+--------+ | expense| +--------+ | meal| | travel| |training| | books| +--------+
DataFrames and Datasets are higher-level abstractions in Spark that provide more optimized execution plans than RDDs, thanks to Spark’s Catalyst optimizer. They offer a more user-friendly syntax for data processing tasks, similar to SQL queries or Pandas DataFrames, provide strong typing guarantees.
What is the difference between broadcast variables and accumulators?
Broadcast variables distribute large read-only data sets to all executor nodes to avoid network data transfer overhead. These shared variables are cached and available on all nodes in a cluster for the tasks to access or use.
from pyspark.context import SparkContext
sc = SparkContext()
statusCodes = sc.broadcast({"A":"Approved", "C":"Cancelled", "R":"Rejected"})
print(sc.parallelize([1, 2, 3, 4, 5], 5).flatMap(lambda x: statuscodes.value).collect())/CodeVxDev
pyspark
spark-submit broadcast.py
11:9:15
[‘A’, ‘C’, ‘R’, ‘A’, ‘C’, ‘R’, ‘A’, ‘C’, ‘R’, ‘A’, ‘C’, ‘R’, ‘A’, ‘C’, ‘R’]
The above code indicates that the list of integers is distributed among the 5 worker nodes. The broadcast variable is then collected from all 5 workers and flattened, resulting in the list containing the keys ‘A’, ‘C’, and ‘R’ repeated five times.
Accumulators, on the other hand, aggregate values across multiple tasks in a fault-tolerant manner, allowing for parallel aggregation operations. Only the driver can access the accumulated value.
from pyspark.context import SparkContext
sc = SparkContext()
length = sc.accumulator(0)
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.foreach(lambda x: length.add(1))
print(length.value)/CodeVxDev
pyspark
spark-submit accumulator.py
11:9:15
5
The length accumulator is created in the above code with an initial value of 0. The foreach method is executed on workers, where the length is incremented by 1. Finally, the driver accesses the length value, which displays the actual length of the list, which is 5.
What are the benefits of using Spark SQL?
Spark SQL supports structured data processing tasks using DataFrames and Datasets, which offer a more user-friendly syntax than RDDs and provide strong typing guarantees. It also integrates well with other big data tools like Hive, allowing for easy querying of large datasets. Spark SQL provides better scalability, fault tolerance, and parallel processing capabilities. It can be used to execute SQL queries, and the results will be returned as a Dataset/DataFrame.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
)
df.createOrReplaceTempView("expenses")
df2 = spark.sql("SELECT expense, date from expenses where cost > 200")
df2.show()/CodeVxDev
pyspark
spark-submit sparksql.py
11:9:15
+--------+----------+ | expense| date| +--------+----------+ |training|2024-08-11| | books|2024-08-12| +--------+----------+
How do you load data into a PySpark DataFrame?
To load data into a PySpark DataFrame, use the spark.read method with different file formats such as CSV, JSON, Parquet, Text, Avro or ORC.
Here is an example of loading a CSV file:
Consider the below pipe delimited csv file.
/CodeVxDev
pyspark
cat test.csv
11:9:15
“expense”|“cost”|“date” “meal”|100|“2024-08-09” “travel”|200|“2024-08-10” “training”|300|“2024-08-11” “books”|400|“2024-08-12”
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df = spark.read.csv("test.csv", sep="|", header=True)
df.show()/CodeVxDev
pyspark
spark-submit load.py
11:9:15
+--------+----+----------+ | expense|cost| date| +--------+----+----------+ | meal| 100|2024-08-09| | travel| 200|2024-08-10| |training| 300|2024-08-11| | books| 400|2024-08-12| +--------+----+----------+
There is also a generic load function spark.read.load that can load the data from the files into the DataFrame. Few examples of the load function are given below.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df1 = spark.read.load("test.csv", format="csv")
df2 = spark.read.load("test.orc", format="orc")
df3 = spark.read.load("test.parquet", format="parquet")
df4 = spark.read.load("test.json", format="json")How do you filter data in a PySpark DataFrame?
To filter data in a PySpark DataFrame, use the filter method and pass a boolean expression as an argument. Here is an example of filtering data where the cost column is greater than or equal to 200:
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
)
print("Original DataFrame")
df.show()
print("Filtered DataFrame")
df2 = df.filter(df.cost >= 200)
df2.show()/CodeVxDev
pyspark
spark-submit filter.py
11:9:15
Original DataFrame +----+----------+--------+ |cost| date| expense| +----+----------+--------+ | 100|2024-08-09| meal| | 200|2024-08-10| travel| | 300|2024-08-11|training| | 400|2024-08-12| books| +----+----------+--------+ Filtered DataFrame +----+----------+--------+ |cost| date| expense| +----+----------+--------+ | 200|2024-08-10| travel| | 300|2024-08-11|training| | 400|2024-08-12| books| +----+----------+--------+
How do you perform aggregation operations in PySpark DataFrame?
To perform aggregation operations in a PySpark DataFrame, you can use the groupBy and agg methods. Here is an example of calculating the average and total spend on each type of expense:
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql import functions as F
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
{"expense": "meal", "cost": 300, "date": "2024-08-13"},
{"expense": "travel", "cost": 600, "date": "2024-08-14"},
{"expense": "travel", "cost": 200, "date": "2024-08-15"},
{"expense": "training", "cost": 100, "date": "2024-08-16"},
]
)
df_avg: DataFrame = (
df.groupBy("expense").agg(F.avg("cost").alias("average_expense"))
).join(df.groupBy("expense").agg(F.sum("cost").alias("total_expense")), on="expense")
df_avg.show()/CodeVxDev
pyspark
spark-submit aggregate.py
11:9:15
+--------+-----------------+-------------+ | expense| average_expense|total_expense| +--------+-----------------+-------------+ | meal| 200.0| 400| | travel|333.3333333333333| 1000| |training| 200.0| 400| | books| 400.0| 400| +--------+-----------------+-------------+
Several aggregation functions and methods are available in PySpark. The most commonly used are sum, min, max, avg, and count.
How do you handle null values in PySpark DataFrames?
When working with null values in a PySpark DataFrame, you have a few options. You can use the na.fill or fillna method to replace missing values with a default value. Alternatively, you can use the dropna or drop.fill method to drop rows containing missing values.
Here’s an example of replacing null values in the paid column with the value false and another DataFrame that contains non null values:
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql import functions as F
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09", "paid": True},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11", "paid": True},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
{"expense": "meal", "cost": 300, "date": "2024-08-13", "paid": True},
{"expense": "travel", "cost": 600, "date": "2024-08-14"},
{"expense": "travel", "cost": 200, "date": "2024-08-15", "paid": True},
{"expense": "training", "cost": 100, "date": "2024-08-16"},
]
)
# DF with default paid value as false for null.
df.fillna(False).show()
# df.na.fill(False)
# DF, which contains only the paid expenses.
df.dropna().show()
# df.na.drop() /CodeVxDev
pyspark
spark-submit nulls.py
11:9:15
DF with default paid value as false for null. +----+----------+--------+-----+ |cost| date| expense| paid| +----+----------+--------+-----+ | 100|2024-08-09| meal| true| | 200|2024-08-10| travel|false| | 300|2024-08-11|training| true| | 400|2024-08-12| books|false| | 300|2024-08-13| meal| true| | 600|2024-08-14| travel|false| | 200|2024-08-15| travel| true| | 100|2024-08-16|training|false| +----+----------+--------+-----+
DF, which contains only the paid expenses. +----+----------+--------+----+ |cost| date| expense|paid| +----+----------+--------+----+ | 100|2024-08-09| meal|true| | 300|2024-08-11|training|true| | 300|2024-08-13| meal|true| | 200|2024-08-15| travel|true| +----+----------+--------+----+
How do you join two PySpark DataFrames? What are the different types of joins in PySpark?
To join two PySpark DataFrames, you can use the join method and pass a join type as an argument. The join types available are inner, left, right, full, semi, cross and anti.
Here are the examples of performing different types of joins:
Let’s create two DataFrames, as shown below. We will perform different joins on the two DataFrames described below and see how they work.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df_expenses: DataFrame = spark.createDataFrame(
[
{"id": 1, "expense": "meal", "cost": 100, "date": "2024-08-09", "paid": True},
{"id": 2, "expense": "travel", "cost": 200, "date": "2024-08-10"},
{"id": 3,"expense": "training","cost": 300,"date": "2024-08-11","paid": True},
{"id": 4, "expense": "books", "cost": 400, "date": "2024-08-12"},
{"id": 5, "expense": "meal", "cost": 300, "date": "2024-08-13", "paid": True},
{"id": 6, "expense": "travel", "cost": 600, "date": "2024-08-14"},
{"id": 7, "expense": "travel", "cost": 200, "date": "2024-08-15", "paid": True},
{"id": 8, "expense": "training", "cost": 100, "date": "2024-08-16"},
]
)
df_approvals: DataFrame = spark.createDataFrame(
[
{"id": 1, "status": "approved", "approval_date": "2024-08-09", "expense_id": 1},
{"id": 2, "status": "approved", "approval_date": "2024-08-11", "expense_id": 3},
{"id": 3, "status": "approved", "approval_date": "2024-08-13", "expense_id": 5},
{"id": 4, "status": "approved", "approval_date": "2024-08-15", "expense_id": 7},
{"id": 5, "status": "approved", "approval_date": "2024-08-16", "expense_id": 8},
{"id": 6, "status": "approved", "approval_date": "2024-08-17", "expense_id": 9},
{"id": 7,"status": "approved","approval_date": "2024-08-18","expense_id": 10},
{"id": 8,"status": "approved","approval_date": "2024-08-19","expense_id": 11},
]
)I have also demonstrated the same joins using Spark SQL to show how they appear as SQL queries.
- Inner: It’s the default join type. We have already seen an example of an inner join operation in the instance for aggregating DataFrame values. The “inner join” operation selects rows with matching values in both related DataFrames.
df_expenses.join(
df_approvals, how="inner", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 INNER JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+---+----+-------------+----------+---+--------+ |cost| date| expense| id|paid|approval_date|expense_id| id| status| +----+----------+--------+---+----+-------------+----------+---+--------+ | 100|2024-08-09| meal| 1|true| 2024-08-09| 1| 1|approved| | 300|2024-08-11|training| 3|true| 2024-08-11| 3| 2|approved| | 300|2024-08-13| meal| 5|true| 2024-08-13| 5| 3|approved| | 200|2024-08-15| travel| 7|true| 2024-08-15| 7| 4|approved| | 100|2024-08-16|training| 8|NULL| 2024-08-16| 8| 5|approved| +----+----------+--------+---+----+-------------+----------+---+--------+
- Full: A full/outer join returns all matched and unmatched values from both DataFrames and appends NULL if there is no match.
df_expenses.join(
df_approvals, how="full", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 FULL JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+----+----+-------------+----------+----+--------+ |cost| date| expense| id|paid|approval_date|expense_id| id| status| +----+----------+--------+----+----+-------------+----------+----+--------+ | 100|2024-08-09| meal| 1|true| 2024-08-09| 1| 1|approved| | 200|2024-08-10| travel| 2|NULL| NULL| NULL|NULL| NULL| | 300|2024-08-11|training| 3|true| 2024-08-11| 3| 2|approved| | 400|2024-08-12| books| 4|NULL| NULL| NULL|NULL| NULL| | 300|2024-08-13| meal| 5|true| 2024-08-13| 5| 3|approved| | 600|2024-08-14| travel| 6|NULL| NULL| NULL|NULL| NULL| | 200|2024-08-15| travel| 7|true| 2024-08-15| 7| 4|approved| | 100|2024-08-16|training| 8|NULL| 2024-08-16| 8| 5|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-17| 9| 6|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-18| 10| 7|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-19| 11| 8|approved| +----+----------+--------+----+----+-------------+----------+----+--------+
- Left: A left join brings in all the records from the left DataFrame and matching records from the right DataFrame. If there is no match, it simply adds a NULL instead. It is also known as the left outer join.
df_expenses.join(
df_approvals, how="left", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 LEFT JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+---+----+-------------+----------+----+--------+ |cost| date| expense| id|paid|approval_date|expense_id| id| status| +----+----------+--------+---+----+-------------+----------+----+--------+ | 100|2024-08-09| meal| 1|true| 2024-08-09| 1| 1|approved| | 200|2024-08-10| travel| 2|NULL| NULL| NULL|NULL| NULL| | 300|2024-08-11|training| 3|true| 2024-08-11| 3| 2|approved| | 400|2024-08-12| books| 4|NULL| NULL| NULL|NULL| NULL| | 300|2024-08-13| meal| 5|true| 2024-08-13| 5| 3|approved| | 600|2024-08-14| travel| 6|NULL| NULL| NULL|NULL| NULL| | 200|2024-08-15| travel| 7|true| 2024-08-15| 7| 4|approved| | 100|2024-08-16|training| 8|NULL| 2024-08-16| 8| 5|approved| +----+----------+--------+---+----+-------------+----------+----+--------+
- Right: A right join returns all the values from the right DataFrame while also getting the matching values from the left DataFrame. If there is no match, it adds a NULL. It is also called the right outer join.
df_expenses.join(
df_approvals, how="right", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 RIGHT JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+----+----+-------------+----------+---+--------+ |cost| date| expense| id|paid|approval_date|expense_id| id| status| +----+----------+--------+----+----+-------------+----------+---+--------+ | 100|2024-08-09| meal| 1|true| 2024-08-09| 1| 1|approved| | 300|2024-08-11|training| 3|true| 2024-08-11| 3| 2|approved| | 300|2024-08-13| meal| 5|true| 2024-08-13| 5| 3|approved| | 200|2024-08-15| travel| 7|true| 2024-08-15| 7| 4|approved| | 100|2024-08-16|training| 8|NULL| 2024-08-16| 8| 5|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-17| 9| 6|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-18| 10| 7|approved| |NULL| NULL| NULL|NULL|NULL| 2024-08-19| 11| 8|approved| +----+----------+--------+----+----+-------------+----------+---+--------+
- Cross: A cross join produces the Cartesian product of two relations. This means it combines every row from the first DataFrame with every row from the second DataFrame.
df_expenses.join(
df_approvals, how="cross"
).show()
spark.sql(
"SELECT * FROM {expenses} e1 CROSS JOIN {approvals} a1",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+---+----+-------------+----------+---+--------+ |cost| date| expense| id|paid|approval_date|expense_id| id| status| +----+----------+--------+---+----+-------------+----------+---+--------+ | 100|2024-08-09| meal| 1|true| 2024-08-09| 1| 1|approved| | 100|2024-08-09| meal| 1|true| 2024-08-11| 3| 2|approved| | 100|2024-08-09| meal| 1|true| 2024-08-13| 5| 3|approved| | 100|2024-08-09| meal| 1|true| 2024-08-15| 7| 4|approved| | 100|2024-08-09| meal| 1|true| 2024-08-16| 8| 5|approved| | 100|2024-08-09| meal| 1|true| 2024-08-17| 9| 6|approved| | 100|2024-08-09| meal| 1|true| 2024-08-18| 10| 7|approved| | 100|2024-08-09| meal| 1|true| 2024-08-19| 11| 8|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-09| 1| 1|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-11| 3| 2|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-13| 5| 3|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-15| 7| 4|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-16| 8| 5|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-17| 9| 6|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-18| 10| 7|approved| | 200|2024-08-10| travel| 2|NULL| 2024-08-19| 11| 8|approved| | 300|2024-08-11|training| 3|true| 2024-08-09| 1| 1|approved| | 300|2024-08-11|training| 3|true| 2024-08-11| 3| 2|approved| | 300|2024-08-11|training| 3|true| 2024-08-13| 5| 3|approved| | 300|2024-08-11|training| 3|true| 2024-08-15| 7| 4|approved| +----+----------+--------+---+----+-------------+----------+---+--------+ only showing top 20 rows
- Semi: A semi-join, also called a left semi-join, is a helpful way to get values from the left side of a relation with matching entries on the right side.
df_expenses.join(
df_approvals, how="semi", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 SEMI JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+--------+---+----+ |cost| date| expense| id|paid| +----+----------+--------+---+----+ | 100|2024-08-09| meal| 1|true| | 300|2024-08-11|training| 3|true| | 300|2024-08-13| meal| 5|true| | 200|2024-08-15| travel| 7|true| | 100|2024-08-16|training| 8|NULL| +----+----------+--------+---+----+
- Anti: An anti-join returns values from the left relation that do not match the right. It is also known as a left anti-join.
df_expenses.join(
df_approvals, how="anti", on=df_expenses.id == df_approvals.expense_id
).show()
spark.sql(
"SELECT * FROM {expenses} e1 ANTI JOIN {approvals} a1 ON e1.id = a1.expense_id",
expenses=df_expenses,
approvals=df_approvals,
).show()/CodeVxDev
pyspark
spark-submit joins.py
11:9:15
+----+----------+-------+---+----+ |cost| date|expense| id|paid| +----+----------+-------+---+----+ | 200|2024-08-10| travel| 2|NULL| | 400|2024-08-12| books| 4|NULL| | 600|2024-08-14| travel| 6|NULL| +----+----------+-------+---+----+
How do you save data from a PySpark DataFrame to disk?
To save data from a PySpark DataFrame to disk, you can use the write method with different file formats such as CSV, JSON, Parquet, or ORC.
Here is an example of saving a DataFrame to a csv file:
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
{"expense": "meal", "cost": 300, "date": "2024-08-13"},
{"expense": "travel", "cost": 600, "date": "2024-08-14"},
{"expense": "travel", "cost": 200, "date": "2024-08-15"},
{"expense": "training", "cost": 100, "date": "2024-08-16"},
]
)
df.write.csv("test.csv", sep="|", header=True)There is also a generic save function spark.write.save that can save the data from the DataFrame into the file. Few examples of the save function are given below.
spark.write.save("test.csv", format="csv")
spark.write.save("test.orc", format="orc")
spark.write.save("test.parquet", format="parquet")
spark.write.save("test.json", format="json")How do you partition a PySpark DataFrame? What is the optimal number of partitions?
The optimal number of partitions depends on various factors, such as the size of the data, available resources, and the parallelism level required for the computation task. To partition a PySpark DataFrame, you can use the repartition() method to divide it into multiple partitions based on a specified column or number of partitions.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
)
df2 = df.repartition(numPartitions=2)
print(df2.rdd.getNumPartitions())
df2.write.mode("overwrite").csv("/tmp/repartition")/CodeVxDev
pyspark
spark-submit sparksql.py | ls -al /tmp/repartition
11:9:15
2 -rw-r—r— 1 spark spark 0 Aug 31 14:46 part-00000-6714755b-9d63-4ea7-8ce9-00bfe03dff3a-c000.csv -rw-r—r— 1 spark spark 20 Aug 31 14:46 part-00003-6714755b-9d63-4ea7-8ce9-00bfe03dff3a-c000.csv -rw-r—r— 1 spark spark 0 Aug 31 14:46 _SUCCESS
The partitions can also be created based on the DataFrame column.
How do you perform distributed sorting and aggregation operations in PySpark?
- RDD:
Distributed sorting and aggregation operations can be performed using various RDD (Resilient Distributed Datasets) transformations such as
sortByKey(),mapValues(),reduceByKey(), etc. Transformations in PySpark are lazy, meaning they do not trigger the execution of tasks until an action operation such ascount(),collect(), orsaveAsTextFile()etc., is called. Actions trigger the actual execution of transformations and return results to the driver program for further processing.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
from pyspark import RDD
sc = SparkContext()
spark = SparkSession(sc)
rdd: RDD = (
sc.parallelize([(300, "travel"), (100, "meal"), (200, "training")])
.sortByKey()
.collect()
)
print(rdd)/CodeVxDev
pyspark
spark-submit aggr.py
11:9:15
[(100, ‘meal’), (200, ‘training’), (300, ‘travel’)]
- DataFrame:
As with RDDs, distributed sorting and aggregation operations can be performed on DataFrames using transformations such as
sort(),withColumn(),withColumns(), etc. The transformations, in this case, are lazy as well.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
from pyspark import RDD
sc = SparkContext()
spark = SparkSession(sc)
df: DataFrame = spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
)
df.withColumn("pricey?", df.cost > 250).show()/CodeVxDev
pyspark
spark-submit aggr.py
11:9:15
+----+----------+--------+-------+ |cost| date| expense|pricey?| +----+----------+--------+-------+ | 100|2024-08-09| meal| false| | 200|2024-08-10| travel| false| | 300|2024-08-11|training| true| | 400|2024-08-12| books| true| +----+----------+--------+-------+
How do you optimize PySpark DataFrame performance?
To optimize PySpark DataFrame performance, you can use various techniques such as:
- Caching frequently used DataFrames or RDDs in memory
- Broadcasting large objects to all worker nodes to avoid network data transfer
- Repartitioning the data to balance workload across worker nodes
- Using PySpark’s built-in optimizer, Catalyst, to generate efficient query plans
- Avoiding shuffles and data reorganization operations whenever possible
How do you process graph data in Spark? What is the difference between GraphX and GraphFrames?
GraphX library provides support for distributed graph computations using the Pregel API. This API is a vertex-centric programming model that allows users to define custom logic for each vertex and edge in the graph. It allows users to perform distributed graph computations such as PageRank, connected components, and community detection. GraphX library supports only RDDs and Scala. GraphFrames is another library that supports relational graph processing tasks using DataFrames syntax, allowing for SQL-like queries on graph data. GraphFrames library supports both Python and Scala. It is an external package; hence, it needs to be added as a —packages argument while running. Here is an example of how to use GraphFrames to process graph data.
from graphframes import *
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
sc = SparkContext()
spark = SparkSession(sc)
df_expenses: DataFrame = spark.createDataFrame(
[
{"id": 12, "name": "Alice", "jdate": "2024-08-09"},
{"id": 16, "name": "Bob", "jdate": "2024-08-10"},
{"id": 11, "name": "Mark", "jdate": "2024-08-11"},
{"id": 14, "name": "John", "jdate": "2024-08-12"},
{"id": 17, "name": "Rob", "jdate": "2024-08-13"},
]
)
df_approvals: DataFrame = spark.createDataFrame(
[
{"src": 12, "dst": 16, "relationship": "Manager"},
{"src": 16, "dst": 11, "relationship": "Peer"},
{"src": 12, "dst": 14, "relationship": "Peer"},
{"src": 14, "dst": 17, "relationship": "Manager"},
{"src": 14, "dst": 11, "relationship": "Manager"},
{"src": 11, "dst": 17, "relationship": "Supervisor"},
{"src": 17, "dst": 12, "relationship": "Supervisor"},
]
)
g = GraphFrame(df_expenses, df_approvals)
# Query: Count the number of "Manager" connections in the graph.
print(g.edges.filter("relationship = 'Manager'").count())
# Run PageRank algorithm, and show results.
results = g.pageRank(resetProbability=0.01, maxIter=20)
results.vertices.select("id", "pagerank").show()/CodeVxDev
pyspark
spark-submit --packages graphframes:graphframes:0.8.4-spark3.5-s_2.12 graph.py
11:9:15
3 +---+------------------+ | id| pagerank| +---+------------------+ | 11|1.0932251979492287| | 12| 1.218918370344588| | 14| 0.651567696478227| | 16| 0.651567696478227| | 17|1.3847210387497288| +---+------------------+
How do you perform real-time data processing in Spark?
Spark Streaming is a module that provides real-time data processing capabilities by breaking down continuous data streams into small batches and processing them using the same Spark engine as batch processing tasks. Below is a simple example of Spark streaming API.
from pyspark.context import SparkContext
from pyspark.sql import SparkSession, DataFrame
import time, tempfile
sc = SparkContext()
spark = SparkSession(sc)
with tempfile.TemporaryDirectory() as d:
# Write a temporary text file to read it.
spark.createDataFrame(
[
{"expense": "meal", "cost": 100, "date": "2024-08-09"},
{"expense": "travel", "cost": 200, "date": "2024-08-10"},
{"expense": "training", "cost": 300, "date": "2024-08-11"},
{"expense": "books", "cost": 400, "date": "2024-08-12"},
]
).write.mode("overwrite").format("csv").save(d)
# Start a streaming query to read the CSV file.
q = (
spark.readStream.schema("cost INT, expense STRING, date STRING")
.format("csv")
.load(d)
.writeStream.format("console")
.start()
)
time.sleep(3)
q.stop()/CodeVxDev
pyspark
spark-submit stream.py
11:9:15
+----+----------+--------+ |cost| expense| date| +----+----------+--------+ | 300|2024-08-11|training| | 200|2024-08-10| travel| | 400|2024-08-12| books| | 100|2024-08-09| meal| +----+----------+--------+
How do you perform machine learning tasks in PySpark?
MLlib is a library in PySpark that provides various machine learning algorithms, including regression, classification, clustering, and collaborative filtering. It also includes tools for feature engineering, model evaluation, and hyperparameter tuning.
Iterative machine learning tasks can be performed using the MLlib library’s MLlibPipeline and Estimator classes, chaining multiple transformations and models into a single pipeline. The TFI (Truncated Fine Iteration) algorithm is an optimization technique used to improve the performance of iterative machine learning algorithms in PySpark by reducing the number of iterations required for convergence.
Summary
I hope this blog post acts as a starting point in your interview preparation. I have compiled the most frequently asked questions to which one should know the answers. However, depending on the interviewer, he/she might like to explore your depth of knowledge. All the code in this blog post can be found in this git repo. Please refer to the official spark documentation for more detailed explanations and examples.