Published
- 41 min read
Frequently asked Kafka Interview Questions (2024)
Most commonly asked interview questions on Kafka.
Introduction
These Kafka interview questions cover various aspects of its architecture, core features, performance, and real-world applications. They aim to assess a candidate’s knowledge, hands-on experience, and understanding of best practices in deploying and operating Kafka in production environments.
This guide serves as an entry point for your interview preparation on Apache Kafka.
1. What is Apache Kafka, and what are its primary use cases?
Apache Kafka is an open-source distributed streaming platform designed for building real-time data pipelines and streaming applications. It handles high-throughput, low-latency, and fault-tolerant data feeds with publish-subscribe messaging and storage capabilities.
Apache Kafka provides a scalable and resilient architecture for storing and processing streams of records in real-time. It has several primary use cases:
- Messaging System: Apache Kafka can act as a highly scalable, high-performance messaging system with the ability to handle millions of messages per second and maintain sub-millisecond latencies.
- Data Integration: Kafka enables real-time data integration between various systems like databases, message queues, and other applications by acting as a unified data bus for different services.
- Real-Time Analytics: By using Kafka Streams API or tools like Apache Spark, Apache Flink, or ksqlDB, you can build real-time analytics applications on top of Kafka to process streaming data and generate insights in real-time.
- Event Sourcing: Event sourcing is a pattern where the state of an application is maintained as an evolving sequence of events rather than storing just the current state. Apache Kafka can serve as a robust event store for such systems, allowing applications to rebuild their state from the history of events at any time.
- Log Aggregation: Instead of sending logs directly to log processing services or files, applications can send them to Kafka topics first. Then, using tools like Fluentd or Logstash, you can aggregate and process these logs for further analysis and visualization in systems like Elasticsearch, Splunk or Grafana.
- Microservices Communication: In microservices architectures, services often need to communicate with each other by sending and receiving events. Apache Kafka can act as an event bus that connects different microservices, allowing them to send and receive messages in a loosely coupled way.
- Internet of Things (IoT): IoT systems generate large volumes of data from various sensors, devices, and gateways. Applications built around Apache Kafka can handle this high-velocity data, process it, and create alerts or insights based on real-time information.
- Machine Learning (ML) and Artificial Intelligence (AI): Real-time streaming data in ML/AI systems is essential for making accurate predictions and decisions. Apache Kafka enables the ingestion, storage, and processing of such streaming data, which can be used as input for machine learning models or AI algorithms.
2. Explain the basic architecture of Kafka, including topics, partitions, brokers, producers, and consumers.
Apache Kafka consists of several components: Topics, Partitions, Brokers, Producers, and Consumers, as described below:
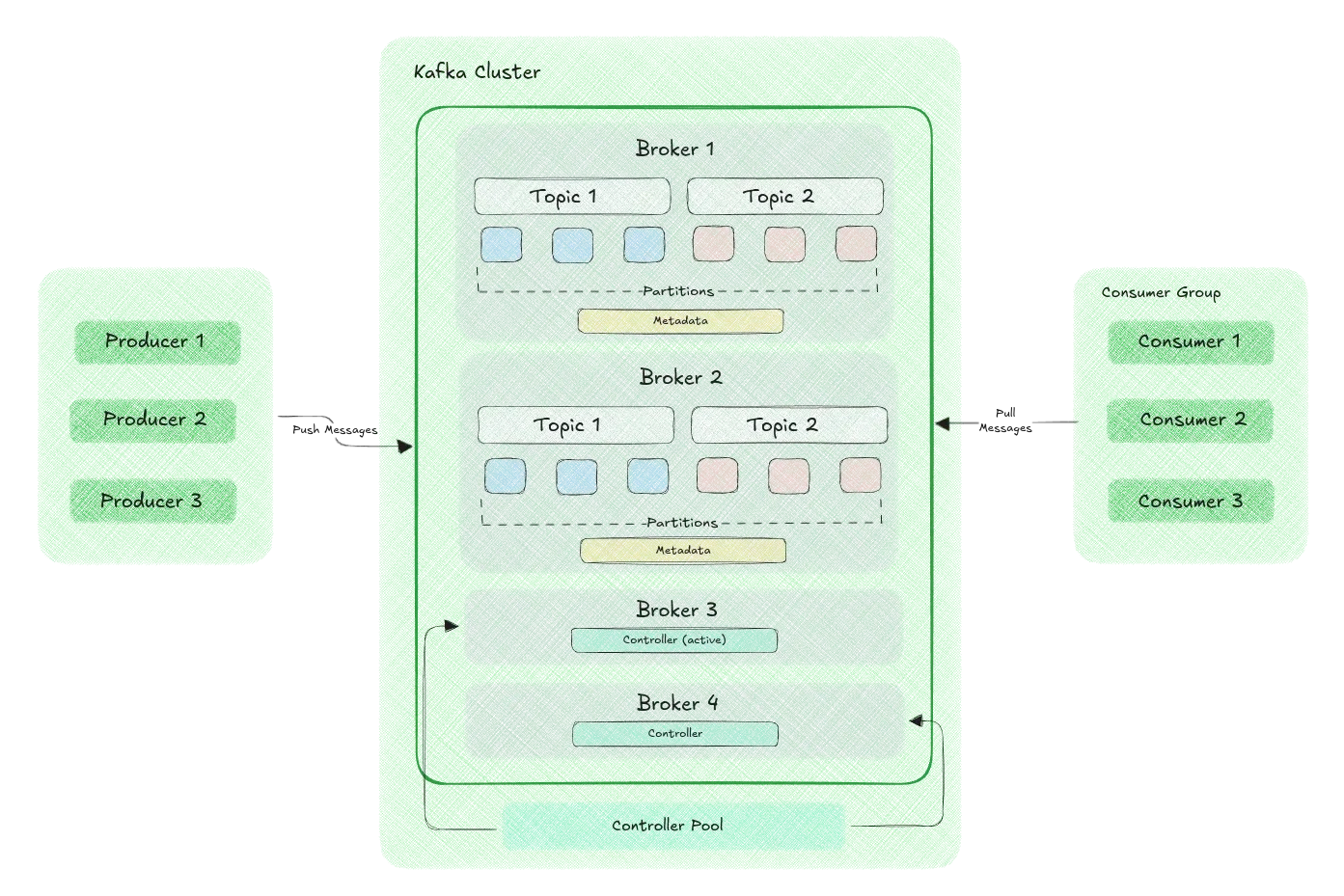
- Topics: A topic in Kafka is a named stream of records that stores messages with the same or no key. When producing or consuming data, you specify the target topic to read from or write to. Applications can have multiple topics for different types of data or events.
- Partitions: A topic is divided into partitions to distribute the load and enable parallel processing. Each partition represents an ordered sequence of messages with unique sequential integer offsets. Producers send messages to specific partitions based on their key or round-robin if no key is specified. Consumers read data from partitions concurrently within the same consumer group, allowing for horizontal scalability and increased throughput.
- Brokers: Kafka runs as a cluster of nodes called brokers that store data, process requests, and provide fault tolerance. Each broker manages one or more topic partitions, ensuring high availability. A Kafka cluster can have multiple brokers to scale horizontally and improve reliability.
- Producers: Producers are applications responsible for sending messages or records to Kafka topics. They can choose which partition to write to based on a key-based hash algorithm, round-robin, or custom logic. Producers also can batch multiple messages into fewer requests and compression for better performance.
- Consumers: Consumers are applications that read data from Kafka topics. They subscribe to one or more topics and receive messages from the partitions assigned to their consumer group. Each message is delivered to a single consumer instance, ensuring no duplication within a group. Consumers maintain an offset for each partition to track their progress and support fault tolerance and replayability of records.
The Kafka architecture enables high-performance data ingestion and processing with low latency due to its scalable design, efficient disk storage, and real-time stream processing capabilities. It can handle billions of events daily while maintaining reliability and resilience, making it a popular choice for various applications in different industries.
3. What are the differences between message queues and publish-subscribe messaging models? How does Kafka combine both in its design?
Message queues and publish-subscribe (pub-sub) messaging models have some key differences:
| Message Queue | Publish-Subscribe |
|---|---|
| Point-to-point communication | Many-to-many communication |
| Consumers compete for messages | Each subscriber gets all messages |
| Single consumer per message | Multiple consumers get the same message |
| Subscription: one consumer, one topic | Subscription: multiple consumers, many topics or wildcards |
| Fan-out is not supported | Implicit fan-out |
Apache Kafka combines elements from the message queue and publish-subscribe messaging models by introducing the concept of partitions within a topic. Here’s how Kafka merges these two designs:
- Message Queue: When producers write messages to Kafka topics without specifying a key, Kafka distributes them evenly among all partitions using a round-robin. Consumers read data from the partitions sequentially and competitively, similar to a message queue model. Each consumer instance in the same group reads different partitions, ensuring no duplication of messages within a group.
- Publish-Subscribe: If producers specify a key when writing messages to Kafka topics, Kafka uses a consistent hashing algorithm to distribute those messages to the same partition, allowing consumers to read all related messages. In this case, multiple consumers can subscribe to the same topic and partitions, receiving the same set of messages, as in the pub-sub model.
In essence, Kafka’s design combines elements from the message queue and publish-subscribe messaging models, allowing it to exploit its strengths. Producers and consumers can use a point-to-point or many-to-many communication style based on their use case requirements and the specified keys for messages. This flexible architecture provides increased scalability, fault tolerance, and performance for real-time data processing scenarios.
4. Explain what KRaft is and how it replaces a zookeeper in Kafka.
KRaft, short for Kafka Raft Metadata mode, is a consensus algorithm and mode of operation introduced in Apache Kafka to manage metadata and coordinate the cluster. It is designed to replace ZooKeeper, which was previously used for metadata management, leader election, and cluster coordination. Here’s how KRaft replaces ZooKeeper in Kafka:
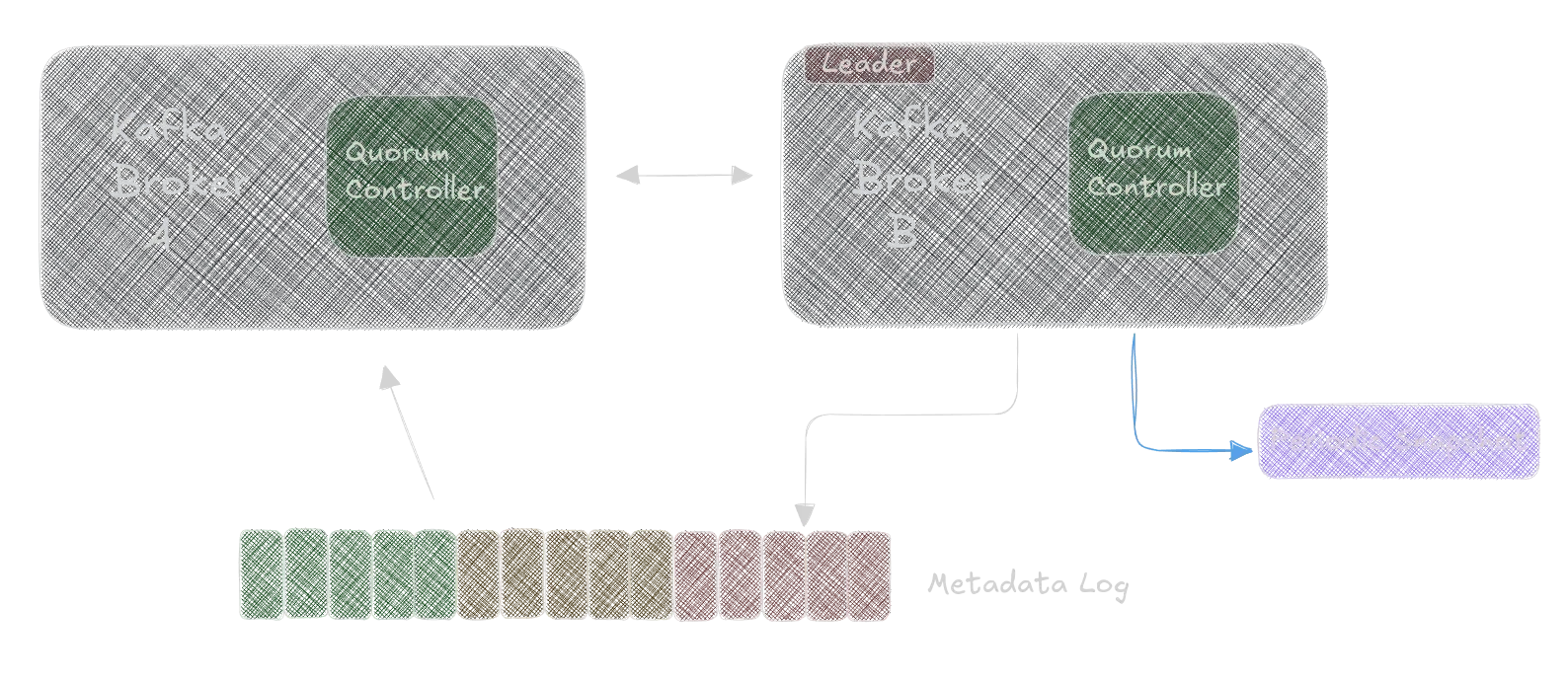
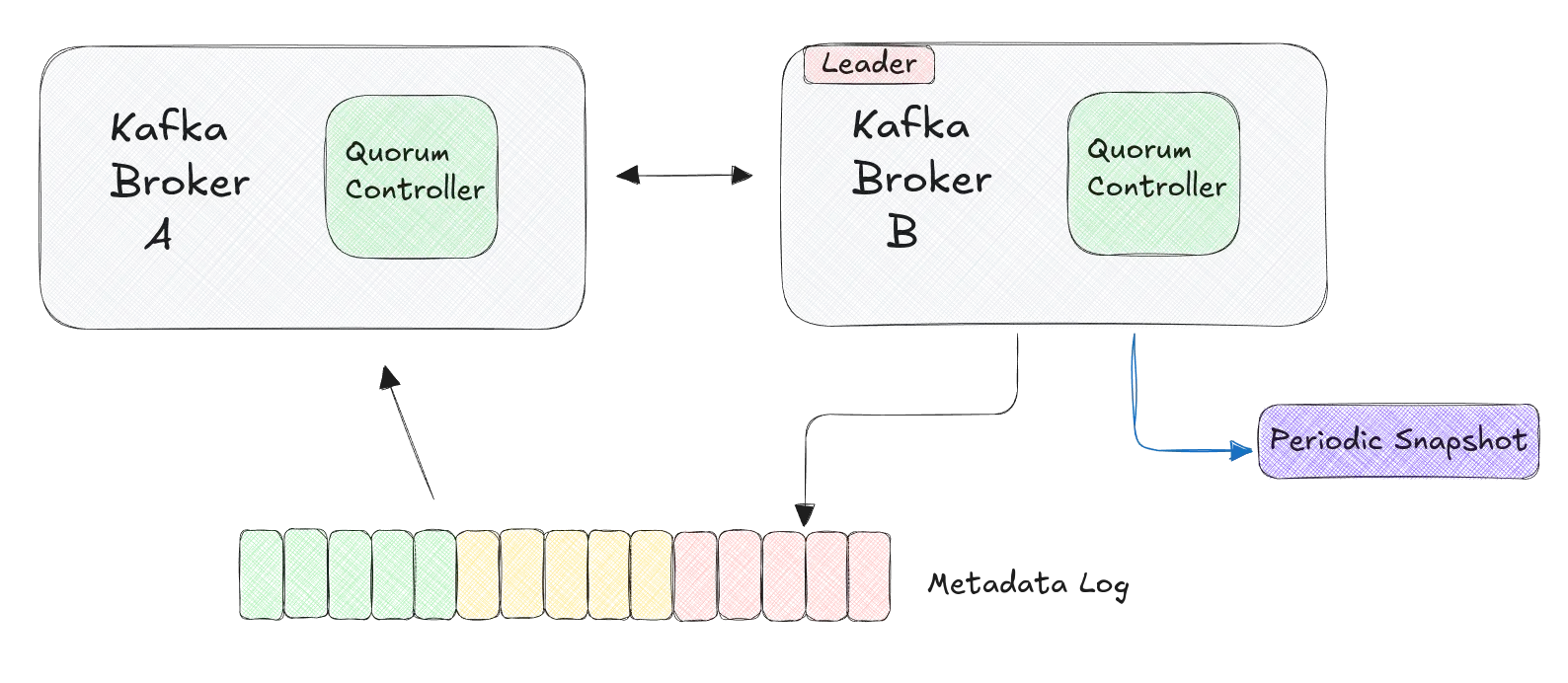
- Metadata Management:
- ZooKeeper: Traditionally, Kafka used ZooKeeper to store metadata about topics, partitions, brokers, and consumer groups. ZooKeeper acted as a centralized store for this critical information.
- KRaft: With KRaft, metadata is stored and managed directly within the Kafka brokers themselves. This eliminates the need for an external system like ZooKeeper.
- Leader Election:
- ZooKeeper: ZooKeeper was responsible for electing the controller broker, which managed the cluster’s metadata and coordinated activities like partition leadership.
- KRaft: KRaft handles leader elections internally using the Raft consensus algorithm. The Kafka brokers elect a controller (the active controller), ensuring high availability and fault tolerance.
- Cluster Coordination:
- ZooKeeper: ZooKeeper provided a centralized point for coordinating various activities within the Kafka cluster, such as broker registration, topic creation, and partition reassignment.
- KRaft: KRaft manages these coordination tasks directly within the Kafka cluster. The active controller broker is responsible for these tasks, and the Raft algorithm ensures that the cluster remains consistent and available.
- Simplified Architecture:
- ZooKeeper: Using ZooKeeper added complexity to Kafka’s architecture, requiring additional operational overhead and potential points of failure.
- KRaft: By integrating metadata management and cluster coordination directly into Kafka, KRaft simplifies the architecture. This reduces operational complexity and potential points of failure.
- Performance and Scalability:
- ZooKeeper: While ZooKeeper is robust, it can become a bottleneck for massive Kafka clusters due to its centralized nature.
- KRaft: KRaft is designed to scale better with large clusters, as it distributes the metadata management and coordination tasks across the Kafka brokers themselves.
Benefits of KRaft:
- Simplified Operations: Removing the dependency on ZooKeeper simplifies the deployment and management of Kafka clusters.
- Improved Scalability: KRaft’s distributed nature allows for better scalability, especially in large clusters.
- Enhanced Fault Tolerance: The Raft consensus algorithm ensures high availability and fault tolerance within the Kafka cluster.
- Reduced Latency: By managing metadata and coordination tasks directly within Kafka, KRaft can reduce latency and improve performance.
5. Explain how producers send messages to Kafka topics. Discuss partitioning strategies, key serialization, and the importance of batching.
Producers send messages to Kafka topics by specifying the topic name and configuration settings like the number of partitions or the key serializer. Here’s a description of these concepts:
- Partitioning Strategies: Producers can determine which partition to write to for each message based on different strategies:
- Key-based: The producer uses a hash function to map messages consistently with a specific key to a specific partition. This strategy ensures that related messages are stored together, simplifying data processing and allowing multiple consumers to read the same set of messages (pub-sub model).
- Round-robin: When messages don’t have a key, or you want to distribute them evenly across partitions, producers can use the round-robin strategy. This method randomly selects a partition for each message while ensuring an equal number of messages per partition over time.
- Custom logic: Producers can also implement custom logic for choosing partitions based on specific business rules or requirements.
- Key Serialization: Producers must serialize the key and value before sending a key-value pair to Kafka using an appropriate serializer implementation. Common choices include Java’s built-in
ByteArraySerializer, JSON serializers, Avro serializers, or Protobuf serializers. A consistent serialization format enables efficient storage and processing in Kafka while ensuring interoperability between different applications and programming languages. - Batching: To improve performance, producers can aggregate multiple messages into batches before sending them to Kafka brokers. This strategy reduces the number of requests the producer makes, allowing for better throughput and lower latency. Key benefits of batching include:
- Reduced network overhead: By sending fewer but larger requests, producers reduce the impact of network latencies and improve overall performance.
- Better compression efficiency: Aggregating multiple messages into a single batch allows for more effective data compression techniques, further reducing message size and improving network utilization.
When configuring producers, it is essential to consider batching settings like linger.ms (delay before sending the batch) or batch.size (maximum number of bytes per batch). Optimizing these parameters can lead to significant performance improvements while minimizing trade-offs between latency and throughput.
Here’s an example Java code snippet demonstrating how a Kafka producer sends messages to a topic using key-based partitioning, JSON serialization, and configuring batch settings:
package com.mycompany.app;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
public class App {
public static void main(String[] args) throws JsonProcessingException {
// Create a Kafka producer with JSON serializers and batch settings
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.RETRIES_CONFIG, 3);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 16KB
props.put(ProducerConfig.LINGER_MS_CONFIG, 5); // Delay before sending the batch (in ms)
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Create an example JSON message with key-based partitioning
ObjectMapper mapper = new ObjectMapper();
MyMessage msg = new MyMessage("message-1", "Hello, World!");
String jsonMsg = mapper.writeValueAsString(msg);
ProducerRecord<String, String> record = new ProducerRecord<>("my-topic",
"message-1", jsonMsg);
// Send the message to Kafka
producer.send(record);
producer.flush();
producer.close();
}
}/CodeVxDev
kafka
./kafka-console-consumer.sh --topic my-topic --from-beginning --bootstrap-server localhost:9092
11:9:15
{“value”:“message-1”,“key”:“Hello, World!“}
In this example, the MyMessage class is a simple Java bean containing two fields: key and value. The producer sends messages with key-based partitioning, JSON serialization, and optimized batch settings for better performance.
6. How do consumers read data from Kafka? Discuss consumer groups, offset management, and record fetching in detail.
Consumers read data from Kafka by joining a consumer group, subscribing to one or more topics, and consuming records from their assigned partitions. Here’s a detailed description of these concepts:
- Consumer Groups: A consumer group is a logical collection of consumers working together as a single entity to consume records from Kafka topics. Each consumer within the group is responsible for processing messages from specific partitions in the topic subscriptions. Kafka enables horizontal scaling and fault tolerance by dividing message consumption among multiple consumers.
- Offset Management: Offsets are positions that record which messages have been consumed within a partition. Consumers maintain offsets to resume processing from the correct position after failures or restarts. Offset management can be performed automatically (managed by Kafka) or manually (controlled by consumers).
- Automatic: When automatic offset management is enabled, Kafka stores consumer group offsets in special topic partitions called
__consumer_offsets. Consumers update their offsets after processing a batch of records. This approach simplifies application logic but reduces control over offsets and makes it more challenging to implement custom strategies like replaying messages or resetting offset positions. - Manual: When manual offset management is used, consumers are responsible for updating their own offset positions within ZooKeeper or Kafka’s
__consumer_offsetstopic partitions. This method provides more control and flexibility over the consumption process but requires additional application logic to maintain and store offsets reliably.
- Automatic: When automatic offset management is enabled, Kafka stores consumer group offsets in special topic partitions called
- Record Fetching: Consumers fetch records from a partition by specifying an offset position. When starting up, consumers initially poll Kafka for metadata about their assigned partitions and current offset positions. Then, they perform the following actions:
- Initial Fetch: If a consumer starts at the beginning of a topic or is rebalancing during consumption, it performs an initial fetch to retrieve all records from the partition’s start position.
- Subsequent Fetches: Consumers periodically poll Kafka for new records based on their current offset positions after consuming some records. Polling intervals can be controlled using configuration settings like
fetch.min.bytesormax.poll.interval.ms. Consumers receive messages from the partition’s committed offset position to the next record with a higher offset during each fetch. - Offset Commit: After processing a batch of records, consumers commit their new offset positions to Kafka. This action ensures they resume consumption from the correct location after failures or restarts.Committing offsets too frequently can lead to performance degradation due to additional network traffic and disk I/O. In contrast, infrequent commits may cause data loss if a consumer fails before committing its latest positions.
Here’s an example Java code snippet demonstrating how Kafka consumers read messages from a topic using a specific consumer group and automatic offset management:
package com.mycompany.app;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
public class MyConsumer {
public static void main(String[] args) {
// Create a Kafka consumer with JSON deserializers and automatic offset
// management
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); // Start from the beginning of topic
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Subscribe to a topic and consume records indefinitely
consumer.subscribe(Collections.singletonList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: key=%s, value=%s%n",
record.key(), record.value());
}
}
}
}/CodeVxDev
kafka
java com.mycompany.app.MyConsumer
11:9:15
Received message: key=message-1, value={“value”:“message-1”,“key”:“Hello, World!“}
In this example, the MyConsumer class subscribes to a single topic named “my-topic” and consumes records using a specific consumer group with automatic offset management. Consumers start processing messages from the beginning of the topic by setting the auto.offset.reset configuration parameter to “earliest”.
7. What are Kafka’s performance characteristics, such as throughput, latency, scalability, and fault tolerance?
Kafka is designed for high-throughput, low-latency data processing with excellent scalability and fault tolerance. Here’s a detailed overview of these characteristics:
- Throughput: Kafka can handle high message throughput rates due to its batching capabilities, zero-copy serialization, and sequential disk I/O access patterns. Batching multiple records into single requests increases network efficiency by reducing the number of round trips required to send messages between brokers, consumers, or producers. Zero-copy serialization avoids data copies during message transmission, further improving performance. Sequential disk I/O enables fast read and write operations since they don’t compete with random access patterns from other applications.
- Latency: Kafka offers low latency for message processing due to its asynchronous nature and in-memory caching of recent messages. Producers can send data to Kafka without blocking, allowing them to continue generating new messages while waiting for acknowledgements from brokers. Similarly, consumers process messages independently without waiting for other consumer group members to finish their tasks. These design choices contribute to predictable and low latencies in message processing.
- Scalability: Kafka is highly scalable because it partitions topics into multiple segments distributed across a cluster of brokers. Partitioning allows for parallel processing of messages, enabling horizontal scaling by adding more brokers or consumers as needed. By distributing the workload among multiple resources, Kafka ensures that a single point of failure doesn’t limit overall system performance.
- Fault Tolerance: Fault tolerance in Kafka is achieved through data replication and topic partitioning. Each partition can have multiple replicas distributed across different brokers in the cluster, ensuring data availability even if one or more brokers fail. When a broker goes down, the remaining replicas continue serving requests for messages, preserving system reliability and message delivery guarantees. Kafka uses leader-based replication to manage read and write operations, allowing producers and consumers to interact with only the partition leader. This approach simplifies data consistency and reduces the overhead of maintaining multiple writers per partition.
8. Describe the concept of a Consumer Group in Kafka and how it helps with parallel processing.
A Consumer Group is a logical collection of consumers working together to consume records from one or more Kafka topics. It enables parallel processing by dividing topic partitions among consumer group members, allowing them to process messages concurrently without interfering with each other’s work.
Each consumer specifies their group ID when joining a Consumer Group (e.g., my-group). Kafka assigns partitions from the consumed topics to individual consumers within the group based on a partition assignment strategy. The Kafka coordinator handles this process during initial group creation and whenever a rebalancing event occurs due to changes in consumer group membership or topic configurations.
Here’s an example of how parallel processing works with Consumer Groups:
Suppose we have a Kafka topic named “my-topic” with three partitions (P0, P1, P2) and two consumers (C1 and C2) belonging to the same group (my-group). During partition assignment, Kafka distributes the topic’s partitions evenly among available consumers. As a result, Consumer 1 receives Partition 0 (P0), while Consumer 2 processes messages from
Partition 2 (P2). The remaining partition (P1) is unassigned because there are only two consumers in this example.
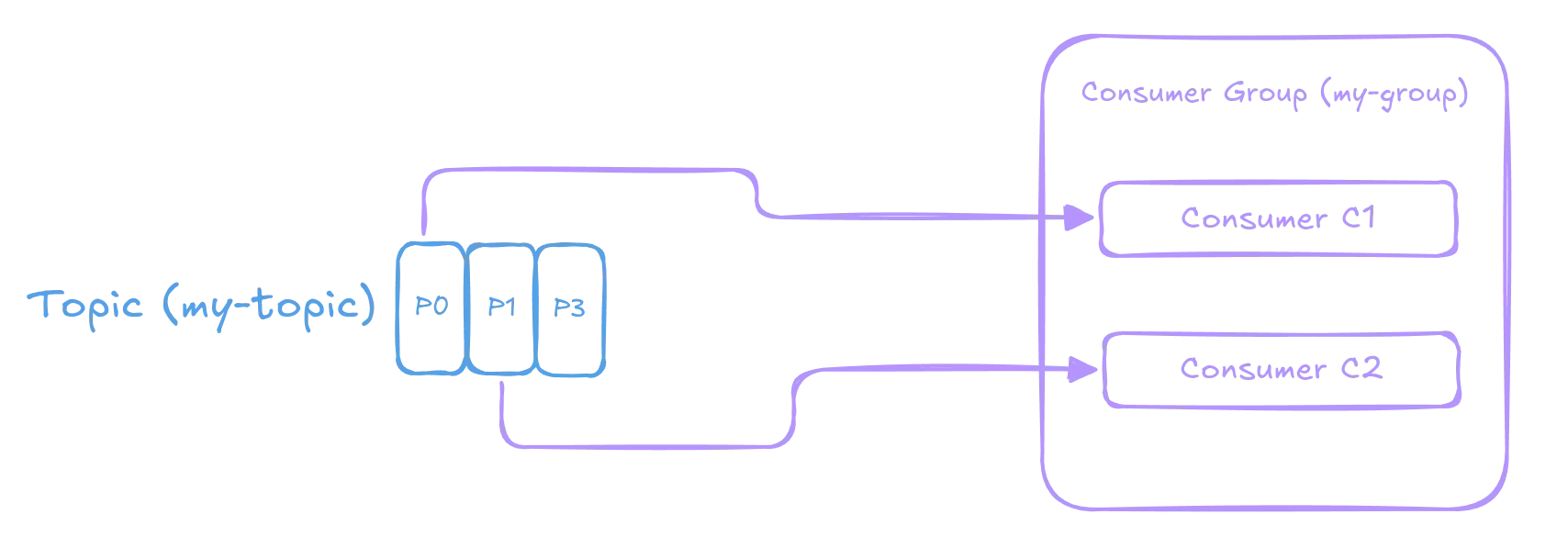
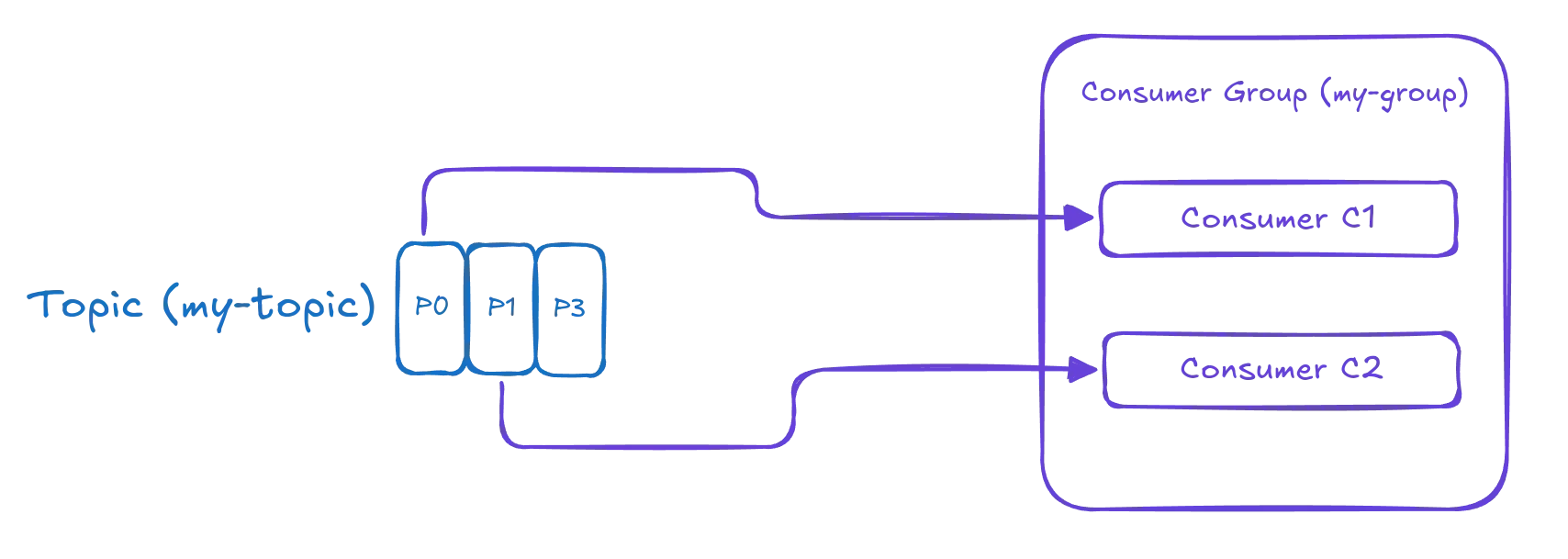
In this configuration, Consumer 1 and 2 read messages from their assigned partitions concurrently, allowing for parallel data processing. This design ensures that consumers within a group work independently without interfering with each other’s tasks since they process distinct subsets of the topic’s partitions. Parallel processing using Consumer Groups improves the overall system throughput by dividing the message processing load among multiple resources (consumers). It also increases fault tolerance since available consumers can take over if one or more members fail, ensuring continuous data processing and availability.
9 .How does Kafka ensure data durability and reliability in message delivery (at least once, at most once, exactly once)?
Apache Kafka provides various configurations to ensure data durability and reliability in message delivery, offering different guarantees depending on application requirements. The primary options for message delivery are:
- At most once: This is the default configuration in Kafka, where messages can be lost but never duplicated. Producers send messages without waiting for acknowledgements from brokers, and consumers process records as soon as they receive them. This approach minimizes latency but risks losing messages if producers or consumers fail before persisting their data.
- At least once: With this configuration, Kafka guarantees that every message will be delivered at least once, although some duplicates might occur. Producers resend messages when they don’t receive acknowledgements from brokers within a specified timeout period or upon detecting errors during transmission. Consumers process records and commit their positions but may consume the same record multiple times if they fail to commit their positions before processing new records.
- Exactly once: Kafka can provide exactly-once message delivery guarantees when integrated with transactional consumers like Apache Spark, Apache Flink, or Kafka Streams. Exactly-once semantics ensure that each message is delivered precisely once without loss or duplication. This approach involves using both producer and consumer transactions to maintain consistency between data sent and received.
To configure these delivery guarantees in Kafka, you can adjust several producer and consumer properties:
Producer configurations:
acks: Controls the number of acknowledgements required from brokers before considering a message successfully sent. Valid values are 0 (at most once), 1 (at least once), or -1 (exactly once with idempotent producers).enable.idempotence: Enables idempotent producer behaviour, which ensures that messages aren’t duplicated due to retries or network issues. This feature is available from Kafka 0.11 onwards and works only when set together with the acks = “all” configuration.transactional.id: Specifies a unique identifier for producer transactions, enabling exactly-once semantics when integrated with transactional consumers.
Consumer configurations:
isolation.level: Controls how messages are consumed from partitions. Valid options are “read_uncommitted” (at most once), “read_committed” (at least once), or “none” (for Kafka 2.5 and later versions).enable.auto.commit: Enables automatic committing of consumer positions at regular intervals. Disable this feature for better control over when to commit positions, ensuring exactly-once semantics in combination with transactional producers.
10 .What are the main configurations for producers, consumers, and brokers to optimize performance? Provide some examples.
To optimize performance in Kafka, you can configure various producer, consumer, and broker settings. Here are some primary configurations and example values:
Producer Configurations:
- Batch Size (batch.size): The number of messages sent together as a single batch to improve network efficiency. A larger batch size increases throughput but also increases latency. Example:
batch.size=16384(16KB) - Linger Time (linger.ms): The time producer waits before sending messages, allowing additional messages to join the current batch. A longer linger time improves throughput but increases latency. Example:
linger.ms=5(5 milliseconds) - Compression Type (compression.type): Enables message compression to reduce network bandwidth usage at the cost of increased CPU consumption for compression and decompression. Example:
compression.type=lz4 - Acknowledgement Level (acks): Controls how many acknowledgements a producer waits from brokers before considering a message successfully sent. A higher value increases reliability and latency. Example:
acks=all - Enable Idempotence (enable.idempotence): Enables idempotent producer behaviour, which ensures messages aren’t duplicated due to retries or network issues. This feature is available from Kafka 0.11 onwards and only works when set together with the acks = “all” configuration. Example:
enable.idempotence=true
Consumer Configurations:
- Fetch Minimum Bytes (fetch.min.bytes): The minimum number of bytes that a consumer will request from brokers when fetching data. A larger value reduces the frequency of fetch requests but increases latency when initially starting consumption or after seeking new positions. Example:
fetch.min.bytes=1048576(1MB) - Fetch Max Bytes (fetch.max.bytes): The maximum number of bytes a consumer will request from brokers per fetch request. A larger value reduces fetch requests’ frequency but may increase consumer memory consumption and latency. Example:
fetch.max.bytes=5242880(5MB) - Fetch Max Wait Time (fetch.max.wait.ms): The maximum time a consumer will wait for new data when fetching from brokers. A larger value increases throughput and latency. Example:
fetch.max.wait.ms=500(500 milliseconds) - Enable Auto Commit (enable.auto.commit): Enables automatic committing of consumer positions at regular intervals. Disable this feature for better control over when to commit positions, reducing the risk of reprocessing messages in case of failures. Example:
enable.auto.commit=false - Max Poll Records (max.poll.records): The maximum number of records a consumer will fetch from brokers per poll request. A larger value increases throughput, memory consumption, and latency for consumers. Example:
max.poll.records=500
Broker Configurations:
- Number of Partitions (num.partitions): Controls the number of partitions in a topic, impacting parallelism and storage requirements per topic. Example:
num.partitions=4 - Replication Factor (replication.factor): Specifies the number of replicas to maintain for each partition. Increasing this value enhances fault tolerance but also raises storage requirements and resource consumption for managing replicas. Example:
replication.factor=3 - Log Segment Size (log.segment.bytes): Defines the size of a log segment file in bytes. Once reached, Kafka creates a new log segment and deletes older segments based on retention policies. A larger value reduces overhead for creating new log segments but increases memory consumption during compaction. Example:
log.segment.bytes=1073741824(1GB) - Log Roll Time (log.roll.hours): The period after which Kafka creates a new log segment regardless of the segment size. A larger value reduces overhead for creating new log segments but increases memory consumption during compaction. Example:
log.roll.hours=24 - Log Retention Time (log.retention.hours): The duration after which Kafka removes old log segments per its retention policies. A larger value improves durability but also increases storage requirements. Example:
log.retention.hours=720(30 days)
These configurations can be adjusted according to specific use cases and performance requirements. Always test changes thoroughly to ensure they have the desired effect on your Kafka cluster’s performance.
11. Explain how you would handle backpressure in Kafka Consumers using the following strategies: a) controlling fetch size, b) using concurrency, and c) managing consumer group members.
Handling backpressure in Kafka consumers involves several strategies that help control the message consumption rate and maintain system stability. Here, I will explain three approaches for handling backpressure:
a) Controlling fetch size: Limiting the number of messages fetched by a consumer per request can reduce the amount of data being processed at any given time, alleviating backpressure. This can be done using the following configuration properties:
fetch.min.bytes: Set a minimum byte limit for fetch requests so that consumers don’t frequently poll for new messages. Increasing this value results in fewer fetches but may introduce some latency.fetch.max.bytes: Limit the maximum number of bytes a consumer will request per fetch request. This setting can help control the data consumption rate and prevent system overload.
b) Using concurrency: Kafka consumers can process messages in parallel using multiple threads or processes to read from different partitions within a topic. You can manage backpressure by adjusting consumer concurrency:
- Increase the
num.consumer.fetchersconfiguration property to enable more fetcher threads per consumer instance. This allows for parallel message retrieval and processing. - Adjust the number of partitions in your topic to better match your consumers’ desired concurrency level. If you have fewer partitions than the maximum desired concurrent tasks, consider increasing the partition count or implementing partitioning strategies such as key-based routing.
- Ensure that consumers are evenly distributed across available partitions by monitoring consumer group membership and adjusting assignments manually if necessary.
c) Managing consumer group members: Efficient distribution of messages among consumers is crucial for handling backpressure. Monitor the following aspects of your consumer groups to ensure an optimal balance:
- Active members: Regularly monitor the number of active consumers in a group and their respective partition assignments. Adjust membership as needed, adding or removing instances based on workload or resource availability changes.
- Rebalancing: Implement custom rebalancing strategies to minimize downtime during the reallocation of partitions when consumers join or leave the group. Strategies such as coordinating consumer shutdowns and using controlled partition assignments can help reduce backpressure during these events.
- Staggered starts: When adding new instances to a consumer group, stagger their startup time to avoid overwhelming the system with excessive concurrent fetches. This can be done manually or through automation tools such as Kubernetes Deployments with rolling updates.
- Expired messages: Regularly monitor and clear out expired messages from your topics to prevent consumers from wasting resources on stale data. Adjust the
log.retention.hoursconfiguration property based on your use case to balance durability and resource consumption.
12. Describe the Streams API concept and its role in building real-time event processing applications on top of Kafka.
Apache Kafka’s Streams API is a powerful library for building scalable, stateful and fault-tolerant stream processing applications on top of Kafka clusters. The Streams API enables developers to create complex data pipelines that perform transformations, aggregations, and real-time event processing using a high-level Java or Scala programming interface.
At its core, the Streams API is built around the concept of a data stream: An unbounded sequence of continuously arriving records representing data produced by various sources. Each record in a data stream consists of a key, value, timestamp, and metadata such as partition and offset information. The Streams API processes these records, transforming them into new data streams that can be consumed by other applications or services.
Here’s an overview of the primary components of the Kafka Streams API:
- Stream Processor Topology: A directed acyclic graph (DAG) representing a processing topology where data flows from source(s) through interconnected nodes to sink(s). Nodes perform various operations like filtering, transformation, aggregation, and windowing on the input records, generating output records.
- Streams Application: A Kafka Streams application is a Java or Scala program using the Streams API that implements a specific processing topology for data streams. The Streams application can be horizontally scalable and fault-tolerant by leveraging Kafka’s partitioning, replication, and consumer group features.
- State Store: A key-value store used to maintain state information in the context of a stream processing application. State stores allow stateful operations like windowed aggregations, joins, or lookups within an application. The Streams API supports in-memory and persistent state stores backed by Kafka topics.
- Transformers and Operators: Pre-built functions for performing common transformations on data streams, such as map, filter, flatMap, join, groupBy, and aggregate. Developers can also implement custom operators to extend the functionality of their processing topology.
- Serdes (Serializer/Deserializer): Object serialization and deserialization interfaces used for converting records between their key-value format in Kafka topics and application-specific data types. Developers must provide Serdes instances for their custom data types to enable the Streams API to work with them.
- Windowing and Time Management: The Streams API supports time-based processing through windowed operations, allowing applications to process records within defined temporal intervals (e.g., tumbling windows, sliding windows, session windows). The library also provides mechanisms for managing clock drift and ensuring consistent time-based processing across multiple nodes in a distributed environment.
The Streams API enables developers to create various streaming applications, including ETL pipelines, anomaly detection systems, recommendation engines, and real-time analytics platforms.
13. Explain the differences between a Connector, Processor, and Transformer in the Kafka Streams API. Provide examples for each.
Connectors are used to interface with external systems, Processors provide fine-grained control over record processing and Transformers offer pre-built functions that simplify common stream processing use cases. Developers can choose the most appropriate building block based on their application requirements. Here’s an explanation of their differences:
- Connectors: A connector is a source or sink that integrates with external systems (e.g., databases, message queues, or file systems) to consume or produce records in Kafka topics. Connectors are designed for reusability and interoperability between various data sources and Kafka clusters. They typically implement the
org.apache.kafka.connect.source.SourceConnectorandorg.apache.kafka.connect.sink.SinkConnectorinterfaces, with a correspondingTaskclass that performs the actual data transfer. Example: A MySQL source connector can read rows from a specified table and emit records to a Kafka topic based on column values. Similarly, an Elasticsearch sink connector can consume records from Kafka topics and index their content in Elasticsearch clusters. - Processors: Processors are the most fundamental building blocks of stream processing applications using the Kafka Streams API. They implement the
org.apache.kafka.streams.processor.api.Processorinterface, which defines a single method calledprocess(), responsible for handling records in a data stream. Processors offer fine-grained control over record processing and enable the creation of custom logic to manipulate or filter records based on business rules. Example: A custom processor can implement logic to transform records based on specific conditions (e.g., converting Celsius to Fahrenheit for temperature records). This custom processor would inherit fromProcessorand override itsprocess()method to perform the required transformation. - Transformers: Transformers are higher-level abstractions than processors, designed to simplify common stream processing use cases by providing pre-built functions that can be easily integrated into a processing topology. They implement the
org.apache.kafka.streams.processor.api.Transformerinterface, which extendsProcessorand introduces some additional helper methods for working with records in a data stream. Example: A custom transformer can implement logic to perform tokenization on incoming records based on specific conditions (e.g., splitting comma-separated values into separate records). This custom transformer would inherit fromTransformerand override itstransform()method, which automatically handles the forwarding of upstream records while allowing for additional processing logic.
14. How does KSQL (now known as ksqlDB) simplify working with Kafka data streams? What are its primary features and benefits?
KSQL (officially named ksqlDB since version 5.0, released in October 2019) is a SQL-like streaming database that works on top of Apache Kafka, enabling developers to process, query, and analyze real-time data streams using a familiar SQL interface. It simplifies working with Kafka data streams by offering an easy-to-use, high-level language for defining complex stream processing applications.
Here are the primary features and benefits of ksqlDB:
- SQL Interface: ksqlDB uses a SQL-like syntax to create, modify, and query data streams and tables. This interface allows developers who are familiar with SQL to quickly build stream processing pipelines without having to learn low-level programming constructs or APIs.
- Data Streaming and Table Processing: ksqlDB supports both data streaming and table processing, making it possible to perform operations on unbounded streams of records (streams) as well as finite sets of records (tables). This support enables developers to create real-time event processing applications with complex queries and joins.
- Materialized Views: ksqlDB supports materialized views that allow users to define the result of a query, which can be queried again later. Materialized views enable efficient state management for stream processing applications and ensure low-latency responses when querying frequently changing data streams.
- Continuous Queries: With ksqlDB, developers can issue continuous queries that automatically update results as new records arrive in the input data streams. This feature simplifies the development of real-time monitoring and alerting systems based on Kafka events.
- Built-in Scalability and Fault Tolerance: As a part of the Kafka ecosystem, ksqlDB inherits its scalability and fault tolerance from underlying Kafka clusters. By default, ksqlDB applications can scale horizontally to handle large volumes of data while providing high availability through replication and partitioning mechanisms.
- Integration with External Systems: ksqlDB provides connectors for integrating external systems (e.g., databases, file systems, message queues), enabling developers to consume or produce records in Kafka topics from various sources and sinks.
- Built-in Functions and Operators: ksqlDB provides various built-in functions and operators for processing data streams and tables. These functions simplify everyday stream processing tasks such as windowing, time management, aggregation, filtering, and transformation.
- Interactive Web UI: ksqlDB provides an interactive web UI that allows developers to visualize and manage their applications, including the creation of new streams or tables, execution of queries, and monitoring of real-time results.
15. Discuss the role of Schema Registry in handling Avro, Protobuf, or JSON data serialization/deserialization for Kafka messages.
The Apache Kafka Schema Registry is a separate component in the Kafka ecosystem that plays a critical role in handling Avro, Protobuf, or JSON data serialization and deserialization for Kafka messages. Its primary function is to manage schemas used for encoding and decoding records exchanged between producers and consumers in Kafka topics. The Schema Registry makes it possible to maintain compatibility when evolving the schemas of data streams over time. It simplifies the development process by providing a centralized repository for storing and retrieving schemas.
Here’s how the Schema Registry works with Avro, Protobuf, or JSON:
- Avro: Avro is a compact binary format that includes its schema as part of each serialized message. The Schema Registry stores Avro schemas, enabling producers to register new schemas and consumers to retrieve them. When a producer sends a record using an Avro schema, the Kafka client serializes the data based on the registered schema and adds it to the value of the Kafka record. When consuming records with Avro data, the consumer’s Kafka client first fetches the corresponding schema from the Schema Registry and then deserializes the message into a native Avro object using that schema.
- Protobuf: Protocol Buffers (protobuf) is another compact binary format that uses schemas to encode and decode messages. Unlike Avro, protobuf does not include its schema within serialized data by default. Instead, schemas are defined in separate
.protofiles that must be compiled into code for encoding and decoding data. The Schema Registry can store the compiled binary version (.bin) of a protobuf schema and associated metadata in the Kafka ecosystem. Producers and consumers then use this registry to obtain schemas when serializing or deserializing messages in Kafka topics. - JSON: While JSON is not as compact as Avro or Protobuf, it remains a popular format for data interchange due to its simplicity and human-readability. The Schema Registry can store JSON schemas (as
.jsonfiles) and provide them to producers and consumers during serialization and deserialization. However, JSON schemas are not automatically included in serialized messages like Avro schemas. Instead, Kafka clients must explicitly include the schema ID as a header when sending records with JSON data. When consuming such records, the Kafka client extracts the schema ID from the headers, retrieves the corresponding JSON schema from the Schema Registry, and deserializes the message content accordingly.
16. Explain how to monitor a Kafka cluster using tools like JMX, Grafana, Prometheus, and Confluent Control Center.
- JMX: Java Management Extensions (JMX) is a Java technology for managing resources like applications, devices, and services. Apache Kafka exposes several JMX metrics that can be used for monitoring purposes. You need to enable JMX on your Kafka brokers to monitor Kafka using JMX. You can then use tools like VisualVM or JConsole to connect to the JMX port of your Kafka broker and inspect various performance metrics related to topics, partitions, replicas, consumers, and producers.
- Grafana: Grafana is an open-source data visualization and monitoring platform. To monitor a Kafka cluster using Grafana, you must first set up a time-series database like Prometheus or InfluxDB to collect and store performance metrics from your Kafka brokers. You can create custom dashboards in Grafana to display various Kafka-related metrics such as throughput, latency, consumer lag, and broker load.
- Prometheus: Prometheus is an open-source time-series database that collects performance metrics from various systems and services. To monitor a Kafka cluster using Prometheus, you need to install the JMX Exporter on your Kafka brokers, which exposes JMX metrics in a format that can be scraped by Prometheus. You can then use Grafana or Prometheus’ built-in visualization tools to create custom dashboards to monitor your Kafka cluster’s various aspects.
- Confluent Control Center: Confluent Control Center is a commercial tool for managing and monitoring Apache Kafka clusters. It provides a user-friendly web interface for monitoring performance metrics related to topics, partitions, replicas, consumers, and producers. Control Center also includes features like alerting, visualization, and debugging tools to help you diagnose and resolve issues in your Kafka cluster.
To monitor a Kafka cluster using these tools, you typically follow these steps:
- Configure JMX on your Kafka brokers: Enable JMX on your Kafka brokers by setting the
JMX_PORTenvironment variable and configuring thekafka.metrics.jmx.registry.nameproperty in yourserver.propertiesfile. - Install Prometheus or InfluxDB: Set up a time-series database to collect and store Kafka performance metrics.
- Configure JMX Exporter: Install the JMX Exporter on your Kafka brokers, which exposes JMX metrics in a format that can be scraped by Prometheus.
- Create custom dashboards in Grafana or Prometheus: Use Grafana or Prometheus’ built-in visualization tools to create custom dashboards for monitoring various aspects of your Kafka cluster. You can also use Confluent Control Center as an alternative to these open-source tools for commercial support and additional features.
- Set up alerting and notification: Use tools like Alertmanager or PagerDuty for setting up alerting and notification rules based on Kafka performance metrics. This step helps you proactively identify and resolve issues in your Kafka cluster before they become critical.
17. Describe standard performance tuning techniques for Kafka brokers, producers, and consumers.
Kafka Broker Tuning:
- Number of Partitions: Increasing the number of partitions per topic can improve throughput by allowing more parallelism in message processing. However, increasing partitions also increases the complexity of managing replicas and leader elections, so finding an optimal balance is crucial.
- Replication Factor: Setting a higher replication factor improves fault tolerance but reduces write performance due to increased network traffic and disk I/O. Choosing an appropriate replication factor based on your availability requirements is essential.
- Producer Acknowledgements: Setting the
acksproperty in Kafka producer configuration determines how many brokers must acknowledge a write before considering it successful. Settingacks=allprovides stronger durability guarantees but reduces write performance. - Log Flush Policy: Configuring log flushes can significantly impact Kafka’s write performance. Setting
log.flush.interval.messagesorlog.flush.interval.msto higher values can improve throughput at the cost of increased risk of data loss in case of a failure. - Batch Size and Linger Time: Increasing batch size and linger time can improve producer throughput by reducing the number of network requests. However, increasing these values also increases message latency.
- Segment Size and Retention Period: Configuring segment size and retention period can impact disk usage, compression ratio, and read performance. Choosing appropriate values based on your use case is essential.
- Compression Type: Enabling compression in Kafka brokers can improve network utilization but increase CPU usage. Choosing an appropriate compression type (none, gzip, snappy, or lz4) based on your use case is essential.
Producer Tuning:
- Batch Size and Linger Time: Increasing batch size and linger time can improve producer throughput by reducing the number of network requests. However, increasing these values also increases message latency.
- Compression Type: Enabling compression in Kafka producers can improve network utilization but increase CPU usage. Choosing an appropriate compression type (none, gzip, snappy, or lz4) based on your use case is essential.
- Key Serialization and Value Serialization: Choosing efficient serialization algorithms for key and value data can significantly impact producer performance. Compact binary formats like Avro or Protobuf can improve throughput by reducing message size.
- Partitioning Strategy: Choosing an appropriate partitioning strategy based on your use case is essential. For example, a custom partitioner that maps keys to partitions can provide better data locality and reduce network traffic.
- Retries and Error Handling: Configuring retries and error handling in Kafka producers can impact message delivery reliability and throughput. Setting appropriate values based on your use case is essential.
Consumer Tuning:
- Fetch Size and Max Partitions per Request: Increasing fetch size and max partitions per request can improve consumer throughput by reducing the number of network requests. However, increasing these values also increases message latency.
- Concurrency Level and Threads Per Data Consumer: Configuring concurrency level and threads per data consumer can significantly impact consumer performance. Increasing these values can provide a better parallelism in message processing but may increase CPU usage and memory consumption.
- Commit Strategy: Choosing an appropriate commit strategy (synchronous, asynchronous, or batch) based on your use case is essential. For example, a synchronous commit strategy provides stronger durability guarantees but reduces throughput.
- Key Deserialization and Value Deserialization: Choosing efficient deserialization algorithms for key and value data can significantly impact consumer performance. Compact binary formats like Avro or Protobuf can improve throughput by reducing message size.
- Consumer Group Rebalancing Strategy: Configuring consumer group rebalancing strategy can impact consumer performance during partition reassignment. Choosing an appropriate strategy based on your use case is essential.
Monitoring Kafka metrics and profiling performance bottlenecks can help you identify areas for optimization and make informed decisions about tuning options.
18. What is MirrorMaker, and how does it help replicate data across different Kafka clusters?
MirrorMaker is a tool provided by Apache Kafka that helps replicate data across multiple Kafka clusters. It works as a consumer-producer pair where the consumer subscribes to topics in one cluster and then produces messages to corresponding topics in another cluster. This way, data can be mirrored or replicated from one Kafka cluster to another with minimal configuration and setup.
MirrorMaker supports various use cases, such as:
- Disaster Recovery: By maintaining a mirror of your production Kafka cluster, you can ensure business continuity in case of an outage or failure.
- Geographic Redundancy: Replicating data across multiple geographically distributed clusters can provide better availability and lower latency for remote consumers.
- Data Isolation: By isolating data into different clusters based on access control policies, security requirements, or compliance regulations, you can improve data privacy and reduce the risk of data breaches.
- Testing and Development: Replicating production data to a test or development environment can help ensure consistency and accuracy in testing and debugging.
MirrorMaker uses Kafka’s consumer and producer APIs to subscribe to topics in the source cluster and produce messages to corresponding topics in the target cluster. It supports various configurations, such as:
- Filtering: You can configure MirrorMaker to filter topics or partitions based on specific rules or patterns.
- Transformations: You can apply transformations to messages during replication, such as modifying headers, adding metadata, or encrypting data.
- Cluster Failover: MirrorMaker supports automatic failover and recovery in case of cluster outages or failures.
- Load Balancing: MirrorMaker supports load balancing across multiple target clusters to distribute replication traffic and improve performance.
- Authentication and Authorization: MirrorMaker supports various authentication mechanisms, such as SASL/PLAIN or SASL/SCRAM, and authorization policies based on ACLs (Access Control Lists).
To use MirrorMaker, you must configure a MirrorMaker topology that includes the source and target clusters, topic mappings, consumer groups, and other options. You can run multiple instances of MirrorMaker in parallel to replicate data across multiple clusters or provide redundancy and high availability.
19. How would you handle upgrades or version migrations of a running Kafka cluster? What tools and strategies would you use?
Upgrading or migrating a running Kafka cluster requires careful planning and execution to minimize downtime, maintain data consistency, and ensure compatibility with new versions. Here are some tools and strategies that I would use to handle upgrades or version migrations of a running Kafka cluster:
- Rolling Upgrade: A rolling upgrade involves upgrading each broker in a Kafka cluster one at a time, ensuring the cluster remains operational and continues processing messages. This approach minimizes downtime and reduces the risk of data loss or inconsistency. Apache Kafka supports rolling upgrades between minor versions (e.g., from 2.6 to 2.7) but not major versions (e.g., from 2.x to 3.x).
- Kafka Tool: The Kafka Tool is a graphical user interface for managing and monitoring Kafka clusters. It includes topic browsing, consumer group management, and version migration that can help simplify the upgrade process. For example, you can use the Kafka Tool to migrate topics from an old cluster to a new cluster with different versions or configurations.
- MirrorMaker: MirrorMaker is a tool for replicating data across multiple Kafka clusters. You can use MirrorMaker to create a mirror of your production cluster on a test or staging environment and then upgrade the test or staging environment to the new version before upgrading the production cluster. This approach provides a safe and controlled way to test and validate the new version before deploying it to production.
- Kafka Manager: Kafka Manager is a web-based tool for managing and monitoring Kafka clusters. It includes topics management, broker configuration, and version migration that can help simplify the upgrade process. For example, you can use Kafka Manager to create new topics with the desired configurations or update existing topics with new settings.
- Kafka Docker Images: Docker images provide a convenient way to deploy and manage Kafka clusters in containers. You can use official or third-party Kafka Docker images to create new versions of your cluster and switch between them using Docker Compose or Kubernetes. This approach provides flexibility and portability across different environments and platforms.
- Data Backup and Recovery: Before starting the upgrade process, you should always backup your data to ensure you can recover from any failures or errors. You can use tools such as Kafka’s MirrorMaker or Replicator to replicate data to a backup cluster or use third-party tools such as Apache NiFi or Confluent Platform to export and import data between clusters.
- Compatibility Testing: Before upgrading your production cluster, you should test the new version in a non-production environment to ensure it is compatible with your applications and workloads. You can use tools like JMeter or Gatling to load-test your Kafka cluster and validate its performance and scalability.
- Monitoring and Alerting: During and after the upgrade process, you should monitor your Kafka cluster using tools such as Prometheus or Grafana to detect any anomalies or issues. You can also set up alerts and notifications to notify you of any critical events or failures.
20. Describe some common challenges when deploying Kafka in production environments and ways to mitigate them (e.g., resource management, networking, security).
- Resource Management: Kafka can consume significant resources such as CPU, memory, and disk space, especially for high-volume and low-latency use cases. Here are some ways to mitigate resource management challenges:
- Use dedicated hardware or cloud instances for Kafka brokers.
- Configure resource quotas and limits for Kafka brokers.
- Monitor resource usage using Prometheus, Grafana, or JMX tools.
- Use autoscaling and load-balancing techniques to distribute traffic and workload across multiple brokers.
- Networking: Kafka relies on TCP-based connections and network infrastructure for communication between producers, consumers, and brokers. Here are some ways to mitigate networking challenges:
- Configure firewall rules and security groups to allow traffic only from authorized sources.
- Use load balancers or reverse proxies to distribute traffic and improve reliability.
- Use VPNs or private networks for inter-cluster communication.
- Use compression, encryption, and other network optimizations to reduce latency and bandwidth usage.
- Security: Kafka handles sensitive data and requires robust security measures to prevent unauthorized access, tampering, or eavesdropping. Here are some ways to mitigate security challenges:
- Enable authentication and authorization using SASL (Simple Authentication and Security Layer) or Kerberos.
- Use SSL/TLS encryption for data in transit and at rest.
- Configure access control policies using ACLs (Access Control Lists).