Published
- 44 min read
Frequently asked Data Engineer Interview Questions (2024)
Most commonly asked interview questions on Data Engineering.
Introduction
In a data engineer interview, the questions typically cover various aspects of data processing, storage, infrastructure management, and distributed systems. These are essential questions, and the interviewer may inquire in detail about each technology and tool you have used, such as Spark, PySpark, Airflow, etc.
Here is a list of the most common questions and their corresponding answers you might encounter during an interview.
What are some key differences between batch and real-time (stream) processing? When would you use one over the other?
Batch processing and real-time (stream) processing are two main approaches for handling and analyzing large volumes of data. The primary differences lie in their processing models, data handling methods, and application scenarios. Here’s a detailed comparison:
-
Processing Model:
- Batch Processing: In batch processing, the system collects,processes, and stores data in batches at regular intervals (e.g., hourly, daily). The processing engine consumes an entire dataset in one go, performing operations on it sequentially or in parallel to produce output.
- Real-time Processing: In real-time processing (also called stream processing), the system continuously ingests, processes, and analyzes data as soon as it arrives. Data is processed in near real-time, with minimal latency between data generation and analysis.
-
Data Handling:
- Batch Processing: Batch systems usually store data on disk or object storage (e.g., HDFS, S3) before processing it. This approach ensures reliable, persistent storage for historical data but requires significant storage resources.
- Real-time Processing: Real-time systems consume data as soon as it’s produced and typically do not store the raw input data unless explicitly configured to do so. They maintain a small buffer of recent events or keep processed results in memory, resulting in lower storage requirements.
-
Latency:
- Batch Processing: Batch processing has higher latency due to the time required to accumulate and store data before processing. The actual processing time depends on the batch size and complexity but can be measured in seconds, minutes, or even hours.
- Real-time Processing: Real-time systems have lower latency, often measuring in milliseconds or a few seconds, making them suitable for near-instantaneous data analysis.
-
Complexity:
- Batch Processing: Batch processing is generally considered less complex than real-time processing, as the system deals with a finite dataset instead of an infinite stream. This approach allows for easier debugging and development.
- Real-time Processing: Real-time systems are more complex due to the need for continuous data ingestion, low latency requirements, and the potential for out-of-order data. These factors can increase development and maintenance costs.
-
Scalability:
- Batch Processing: Batch processing can be highly scalable by parallelizing operations across multiple nodes or clusters. This approach allows batch systems to handle large volumes of data efficiently.
- Real-time Processing: Real-time systems can also scale well, but their performance depends on the processing engine and infrastructure used. They typically require more advanced configuration than batch systems for optimal scalability.
-
Use Cases:
- Batch Processing: Batch processing is suitable for offline data analysis, historical reporting, periodic data aggregation, machine learning training, and other applications where low-to-moderate latency is acceptable.
- Real-time Processing: Real-time processing is ideal for applications requiring immediate feedback or decision-making based on incoming data, such as fraud detection, recommendation systems, IoT monitoring, real-time analytics, and event-driven architectures.
The choice between them depends on the specific use case and its requirements regarding latency, complexity, scalability, and resource usage.
Explain the difference between data at rest and data in motion, and discuss the associated challenges.
Data at Rest refers to data that is stored in a persistent storage systems, such as hard drives, solid-state drives, or object stores (e.g., S3, Google Cloud Storage). This data is not actively processed or transmitted. Data at rest can be accessed, modified, or analyzed later when needed. Common examples of data at rest include relational databases, file systems, NoSQL databases, data warehouses, and object storage services.
Data in Motion, also known as data in transit, refers to data being actively transmitted between two or more locations through a network, such as the internet or an internal corporate network. Data in motion is typically not stored permanently but passed along from one system or application to another for processing, analysis, or storage. Examples of data in motion include data streams, message queues, APIs, and network communication between microservices.
Challenges associated with Data at Rest:
- Security: Data at rest is often a prime target for unauthorized access, theft, or tampering. Ensuring proper encryption, access controls, and audit trails are crucial to maintaining data confidentiality, integrity, and availability.
- Scalability: Storing large volumes of data can become challenging as the data grows. Organizations must invest in scalable storage solutions that accommodate growing datasets while providing reasonable performance.
- Data Quality: Ensuring data quality is another challenge when dealing with data at rest, especially from multiple sources or systems. Establishing data governance policies, implementing data validation checks, and maintaining clean, up-to-date data are essential for successful data management.
- Data Lineage: Understanding the origin, transformations, and usage of data in an organization is critical for regulatory compliance, auditing, and troubleshooting purposes. Maintaining a clear record of data lineage can be challenging when dealing with large datasets and complex data flows.
Challenges associated with Data in Motion:
- Data Integrity: Ensuring data integrity during transmission is crucial for maintaining accurate, consistent information across systems. Techniques such as checksums, data encryption, and message signing can help preserve data integrity.
- Network Latency: Transmitting large volumes of data over a network can introduce significant latency, affecting real-time or near real-time applications’ performance. Optimizing network infrastructure and communication protocols is essential for minimizing this latency.
- Data Loss: Network failures, system crashes, or malicious attacks can lead to data loss during transmission. Implementing redundancy, error correction mechanisms, and resilient network architectures are crucial for ensuring high availability and fault tolerance.
- Scalability: Handling large volumes of data in motion requires scalable network infrastructure and processing engines capable of handling the increased load without sacrificing performance or reliability.
How do you ensure data quality in a data pipeline? Mention specific techniques and tools you have used to address this issue.
Ensuring data quality is crucial for making informed decisions based on accurate, consistent, and reliable information. Implementing effective data quality techniques throughout the data pipeline can help maintain high-quality data and improve overall decision-making capabilities. Here are some specific techniques and tools you can use to address this issue:
- Data Profiling: Analyze the structure, content, and relationships of datasets to gain insights into their quality and identify potential issues or inconsistencies. Tools like Talend Data Quality, Informatica Intelligent Data Platform and Trifacta provide powerful data profiling capabilities.
- Data Validation: Implement validation checks at various stages in the pipeline, such as input validation, format checks, range constraints, and consistency rules. This process ensures that only valid and clean data enters downstream systems or analytics applications. Tools like Apache Beam’s built-in transforms for validation, and Joi can be used for JavaScript-based applications.
- Data Cleansing: Automatically correct or remove inaccurate, inconsistent, or duplicate records to improve data quality. Techniques such as parsing, standardization, normalization, and de-duplication help maintain clean, consistent data. Tools like OpenRefine (formerly Google Refine) offer powerful data cleaning capabilities.
- Data Transformation: Implement transformation logic that converts raw or inconsistent data into a format suitable for analysis and decision-making. Techniques such as data mapping, schema normalization, and aggregation can help improve the usability and quality of data. Tools like Talend Studio, Apache Nifi, and AWS Glue offer extensive data transformation capabilities.
- Data Monitoring: Continuously monitor data pipelines in real time to detect anomalies, inconsistencies, or errors. Implement alerts and notifications for data quality issues, allowing teams to address problems proactively. Tools like Datadog, Splunk, and Elasticsearch can be used for monitoring and alerting purposes.
- Data Governance: Establish policies, procedures, and roles to manage the lifecycle of data within an organization. This process includes defining ownership, access controls, data lineage, retention policies, and data validation rules. Tools like Collibra, Informatica MDM 360, and IBM InfoSphere Information Governance Catalog supports data governance efforts.
- Data Integration: Implement robust data integration strategies that ensure seamless communication between systems, minimizing the risk of data loss or inconsistencies during transmission. Techniques such as API-based integrations, message queues, and event-driven architectures can improve data quality by ensuring accurate data exchange. Tools like Apache Kafka, AWS Kinesis, and Azure Event Hubs can be used for data integration.
- Data Training: Educate users on best practices for data entry, management, and analysis to ensure that data remains clean, accurate, and reliable throughout its lifecycle. This process includes providing training materials, documentation, and user support resources.
By implementing these techniques and tools, organizations can maintain high levels of data quality throughout the data pipeline, enabling informed decision-making based on accurate, consistent information.
Discuss various methods for scaling batch and real-time processing systems. What are their trade-offs?
Scaling batch and real-time processing systems is essential to handle increasing workloads, larger datasets, and more complex analytics or decision-making requirements. Various methods can be employed to achieve scalability in batch and real-time processing systems, each with unique advantages and trade-offs. Here are some common scaling techniques for both scenarios:
Batch Processing Scaling Methods:
- Horizontal Scaling (Sharding): Distribute data across multiple nodes or machines to increase overall system capacity. Each node processes a subset of the data, reducing the processing load on individual machines and allowing the system to handle larger datasets. Trade-offs include increased complexity for managing distributed systems and potential challenges in maintaining data consistency.
- Vertical Scaling (Upgrading Hardware): Increase the computational power or storage capacity of a single machine by adding more memory, faster processors, or additional storage devices. This approach is typically easier to manage than horizontal scaling but can become expensive as hardware upgrades are often costly and limited by physical constraints.
- Parallel Processing: Break down large data processing jobs into smaller, parallelizable tasks that can be executed concurrently on multiple nodes or cores. Parallel processing can significantly reduce processing time for batch operations, enabling faster analytics and decision-making. Trade-offs include the complexity of managing parallel workflows and potential challenges in maintaining data consistency.
- Data Sampling: Analyze a representative subset of the dataset instead of processing the entire dataset to achieve scalability while reducing resource requirements. This approach is particularly suitable for exploratory analytics or decision-making tasks that do not require processing all available data. Trade-offs include reduced accuracy and potential biases in results based on sampling techniques.
Real-Time Processing Scaling Methods:
- Horizontal Scaling (Adding Nodes): Add more machines or nodes to the real-time processing system, distributing incoming data and processing tasks among them. This approach increases overall system capacity and enables handling higher data volumes in real time. Trade-offs include increased complexity for managing distributed systems and potential challenges in maintaining data consistency.
- Load Balancing: Distribute incoming data and processing tasks across multiple nodes or cores to ensure that no single node is overwhelmed by the workload. Load balancing can help improve system performance and maintain real-time processing capabilities under high load conditions. Trade-offs include potential latency increases due to data routing and load distribution.
- Data Streaming: Implement event-driven architectures or message queues that allow for real-time data ingestion, processing, and analytics without storing the entire dataset in memory. Data streaming enables low-latency processing and reduces resource requirements compared to traditional batch processing methods. Trade-offs include increased complexity in managing real-time workflows and potential challenges in maintaining data consistency.
- Real-Time Analytics Engines: Leverage specialized real-time analytics engines such as Apache Flink, Spark Streaming, or Google Cloud Dataflow to manage and process large datasets with low latency. These tools provide built-in support for scalable, real-time processing, simplifying system management but potentially introducing vendor lock-in or increased costs.
- Data Sampling: As in batch processing, data sampling can achieve scalability by analyzing a representative subset of the dataset instead of processing the entire dataset. This approach is particularly suitable for real-time analytics or decision-making tasks that do not require processing all available data. Trade-offs include reduced accuracy and potential biases in results based on sampling techniques.
Selecting the appropriate scaling technique depends on the specific use case, dataset size, required latency, available resources, and desired balance between these factors.
Explain the role of data governance in an organization and how it impacts the work of a data engineer.
Data governance is a set of policies, procedures, roles, and responsibilities that manage the lifecycle of data within an organization. It ensures that data is accurate, consistent, secure, compliant, and readily available for decision-making, analytics, and other business purposes. A well-implemented data governance strategy impacts the work of a data engineer in several ways:
- Data Quality Management: Data governance establishes clear standards, policies, and procedures for ensuring data quality throughout the organization. This involves defining ownership, establishing validation rules, and implementing processes for identifying and addressing data quality issues. A data engineer is responsible for implementing these policies within data pipelines and infrastructure, including designing validation checks, implementing data cleansing techniques, and maintaining clean, consistent data.
- Data Security and Access Control: Data governance includes defining security policies and access controls to protect sensitive information and ensure compliance with regulations such as GDPR, CCPA, or HIPAA. Data engineers are responsible for implementing these controls within the data infrastructure, including designing secure data pipelines, managing user permissions, and ensuring encryption and anonymization techniques are applied where necessary.
- Data Integration and Interoperability: Data governance promotes seamless communication between systems by defining common standards, protocols, and interfaces for data exchange. Data engineers are responsible for implementing these standards in the design of data pipelines, integrations, and APIs to ensure that data is exchanged accurately, consistently, and securely between different applications and platforms.
- Data Lifecycle Management: Data governance includes policies for managing data retention, archiving, backup, and disaster recovery. A data engineer plays a crucial role in implementing these policies by designing robust, scalable data storage solutions and ensuring that data is consistently backed up and readily available when needed.
- Data Lineage and Transparency: Data governance promotes transparency in data handling by tracking data lineage, metadata management, and documentation of data processes. A data engineer is responsible for implementing these capabilities within the data infrastructure, including maintaining logs, tracing data provenance, and documenting data pipelines to ensure that data can be tracked and audited throughout its lifecycle.
- Collaboration with Data Stewards and Business Users: Data governance involves collaboration between different stakeholders in the organization, including IT, business users, and compliance officers. A data engineer works closely with data stewards and other roles responsible for defining data policies and standards to ensure that these requirements are reflected in the design of data infrastructure and processes.
How do you handle schema evolution in your data pipelines? Describe techniques to maintain backward compatibility when changing schemas.
Handling schema evolution is essential to maintaining robust and adaptable data pipelines. Schema changes are inevitable due to evolving business requirements, database updates, or new data sources. To maintain backward compatibility when modifying schemas, you can employ various techniques:
- Schema Validation: Implement schema validation in your data pipelines to ensure incoming data adheres to the expected format and structure. Use libraries like Avro, Protobuf, or JSON Schema to define data structures and validate incoming data. This helps catch unintended changes early on, ensuring backward compatibility with existing applications and processes.
- Versioning: Introduce versioning in your schema definitions to manage breaking changes over time. Maintain separate schemas for different versions and ensure that new versions are compatible with the older ones while allowing for gradual migration of data pipelines and applications to updated schemas. You can maintain different versions within a single schema definition file or use separate files for each version.
- Schema Evolution Strategies: Implement specific evolution strategies based on the nature of changes. Common strategies include:
- Additive Changes (Backward Compatible): Add new fields to the schema without modifying existing ones, allowing downstream components to safely ignore additional information. This is a backwards-compatible approach since older applications and pipelines can continue processing data without interruption.
- Preserving Old Fields (Partially Backward Compatible): When removing or renaming fields, maintain the old field in the schema with a default value or explicitly mark it as deprecated to avoid breaking existing components that still rely on the older version of the schema. This allows downstream applications time to adapt to the change while ensuring backward compatibility for a limited period.
- Backward Incompatible Changes: In some cases, breaking changes may be unavoidable due to significant shifts in data structures or requirements. In such situations, implement a transition plan that includes communication with stakeholders, setting expectations for downtime, and managing the migration of applications and pipelines to the new schema.
- Schema Registry: Use a schema registry like Apache Avro Schema Registry or confluent Schema Registry to manage and track different versions of your schemas. This helps maintain consistency across data sources, ensures that downstream components are aware of schema changes, and enables versioning-based querying and processing in your pipelines.
- Automated Testing: Implement automated testing frameworks for your data pipelines. These tests should verify that new schema versions maintain backward compatibility with existing applications and processes while ensuring the correctness of data transformations, aggregations, or other operations within the pipeline.
- Communication and Collaboration: Collaborate closely with stakeholders, including data engineers, data scientists, and business users, to understand the impact of schema changes on their workflows. Communicate any planned breaking changes well in advance and provide support during migration to new schemas to ensure a smooth transition process.
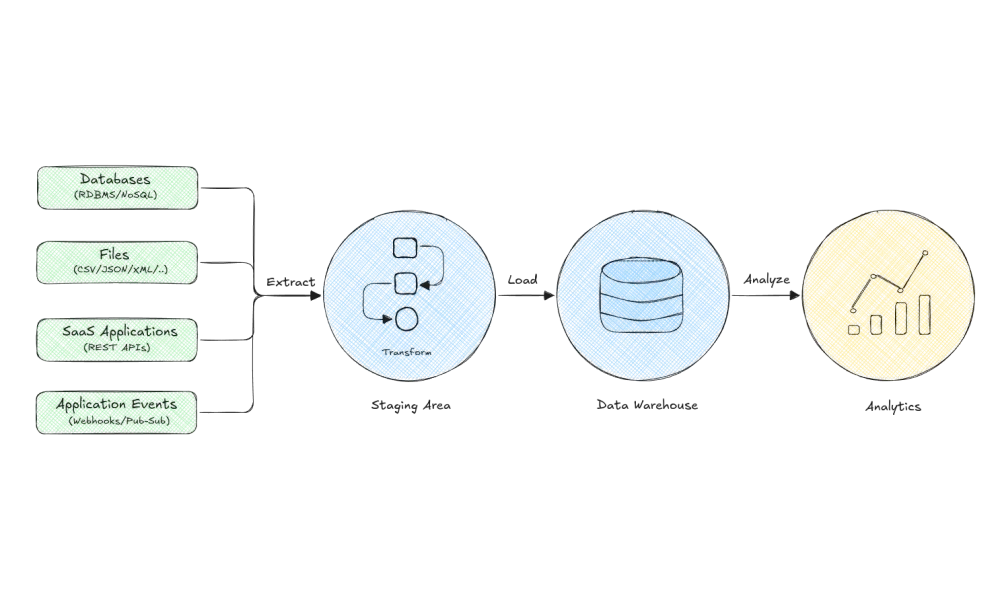
Discuss ETL (Extract, Transform, Load) processes you have worked on in detail, including technologies used, challenges faced, and how they were resolved.
The response to this question should be drawn from your personal project experience. I will cover the fundamentals of the ETL (Extract, Transform, Load) process and discuss potential challenges you may or may not have encountered in your project. This answer is intended to serve as a foundation to help you formulate your own response.
An Extract, Transform, Load (ETL) process is a data integration methodology used for collecting data from various sources, modifying it according to specific business rules and loading it into target systems like data warehouses or databases for downstream consumption by analytics tools, machine learning models, or business intelligence applications.
The ETL process consists of three main steps:
- Extract: Data is sourced from different systems, such as operational databases, SaaS platforms, log files, or APIs using custom connectors, libraries, or pre-built solutions like Apache Nifi, Talend, or Fivetran. This step often involves handling various data formats (e.g., CSV, JSON, XML) and ensuring compatibility with downstream components.
- Transform: The extracted raw data is cleaned, normalized, enriched, and aggregated according to specific business rules using tools like Apache Spark, Trifacta, or Informatica PowerCenter. This step may involve various transformations such as parsing nested structures, handling missing values, resolving inconsistencies, joining multiple datasets, applying calculations, or deriving new features based on the data.
- Load: The transformed data is then loaded into target systems like a data warehouse, databases, or data lakes like Apache Hive, Amazon Redshift, Google BigQuery, or Azure Synapse Analytics. This step may also involve optimizing the loading process for performance and query efficiency by applying techniques like partitioning, bucketing, indexing, or compressing data.
The technologies and tools involved in ETL processes can be categorized into several groups based on their primary functions:
- Data Extraction: Custom connectors, libraries, and tools such as Apache Nifi, Talend, Fivetran, Stitch, or Hevo.
- Data Transformation: Tools like Apache Spark (with PySpark or Scala), Apache Beam, Trifacta, Informatica PowerCenter, Dataiku DSS, or Talend Data Integration.
- Workflow Management: Tools for scheduling and managing ETL tasks, such as Apache Airflow, Luigi, AWS Step Functions, or Google Cloud Composer.
- Data Loading: Tools like Apache Hive, Amazon Redshift, Google BigQuery, Azure Synapse Analytics, PostgreSQL, MySQL, or Oracle databases.
- Data Storage and Querying: Data warehouses (e.g., Amazon Redshift, Snowflake, Google BigQuery), data lakes (e.g., AWS S3, Azure Data Lake Storage), or distributed file systems (e.g., Hadoop Distributed File System).
- Data Quality, Profiling, and Testing: Tools like Apache Beam’s Data Quality API, Talend Data Quality, Trifacta Wrangler, Databricks Delta, or Great Expectations.
- Metadata Management: Tools for managing metadata (e.g., data lineage, data catalogues) such as Collibra, Alation, Amundsen, or Apache Atlas.
- Data Security and Compliance: Tools like AWS Glue DataBrew, Azure Purview, or Google Cloud Dataplex to ensure data privacy, encryption, anonymization, pseudonymization, or compliance with regulations such as GDPR, CCPA, or HIPAA.
The choice of tools and technologies depends on factors like the scale and complexity of the ETL process, the required performance, and cost-efficiency, existing infrastructure, and the team’s expertise.
Potential Challenges:
- Performance: Handling large volumes of data from multiple sources with varying data structures and sizes required efficient processing techniques to ensure timely completion of ETL tasks. We use Spark DataFrames, optimized SQL queries, and Hive partitions to improve query performance during loading.
- Schema Changes: To handle schema evolution, implement versioning and additive strategies to allow downstream components to safely ignore new fields without affecting existing processing logic.
- Data Quality: Ensuring high-quality data required rigorous testing and validation throughout the ETL process. Use automated testing frameworks and PySpark’s built-in data quality functions to validate incoming data against expected schemas, formats, and content.
- Error Handling and Recovery: Error handling during large-scale data processing can be challenging due to complex dependencies and potential loss of data. To address this issue, implement custom exception handling logic in PySpark scripts, allowing for retries, logging, and notifications when errors occur. Additionally, use Airflow’s robust error handling and retry mechanisms to manage failed tasks.
- Security and Compliance: Ensuring data privacy and compliance with regulations like GDPR and CCPA required careful handling of personal information during ETL processing. Implement encryption, anonymization, and pseudonymization techniques as needed, following best practices for secure data management and compliance with relevant regulations.
Explain the concept of data lineage and its importance in data engineering. Describe tools and practices to maintain and manage data lineage.
Data lineage is the ability to trace and understand the origin, transformation history, movement, and lifecycle of data throughout the entire data ecosystem. This includes tracking data as it flows from various sources through ETL processes, transformations, storage systems, and analytics tools to its final consumption or destination.
Data lineage provides valuable insights into how data is manipulated, managed, and used within an organization. Maintaining accurate and up-to-date data lineage information helps teams:
- Improve Data Quality: By understanding the origin, transformations, and dependencies of data, engineers can quickly identify potential issues, pinpoint root causes, and implement corrective measures to ensure high-quality data.
- Enhance Collaboration: Data lineage facilitates communication among teams working on different aspects of data engineering, analytics, or machine learning projects, enabling them to better understand the impact of their work on other components and stakeholders.
- Streamline Auditing and Compliance: Maintaining accurate data lineage records is essential for meeting regulatory requirements like GDPR, CCPA, or HIPAA, as it allows organizations to demonstrate transparency in how they handle personal information and respond to compliance audits.
- Accelerate Debugging and Troubleshooting: Data lineage enables engineers to quickly identify the root cause of issues by tracing data back to its source, transformations, or dependencies. This reduces the time required for debugging, testing, and maintaining complex data systems.
- Optimize Performance and Efficiency: By understanding how data flows through various systems, teams can optimize performance, reduce redundancy, improve resource utilization, and lower costs associated with data processing and storage.
Tools and practices to maintain and manage data lineage include:
- Metadata Management Systems: Centralized metadata repositories like Apache Atlas, Collibra, Alation, or Amundsen that store, catalogue, and document various types of metadata related to data sources, transformations, dependencies, policies, or business rules.
- Data Lineage Visualization Tools: Graphical representations of data lineage using tools like Data lineage in Apache Atlas, Octopai, Informatica Enterprise Data Catalog, or Erwin Data Intelligence, that display the origin, flow, and transformation history of data across systems and processes.
- Automated Data Discovery and Profiling: Tools for automatically discovering, cataloguing, and profiling data assets like AWS Glue DataBrew, Azure Purview, or Talend Data Governance to create and maintain an up-to-date metadata inventory.
- Data Version Control Systems: Git-like repositories that track changes in data definitions, schemas, or transformations over time, such as Apache Hudi, Delta Lake, or Dolt.
- Integration with ETL and Data Processing Tools: Incorporating data lineage tracking within the ETL/ELT tools themselves, using native capabilities in tools like Apache Spark, Apache Beam, Trifacta, Talend Data Integration, or Apache Nifi, to capture metadata and data flow information.
- Data Lineage Best Practices: Implementing best practices for documenting, tracking, and managing data lineage, such as:
- Establishing a consistent naming convention for data assets and processes.
- Documenting each transformation step with detailed descriptions and business rules.
- Continuously updating metadata repositories to reflect changes in the data ecosystem.
- Implementing role-based access control and audit trails to ensure accountability and security.
How would you design a data pipeline with fault tolerance and error handling considerations? What components would you include in such a system, and why?
Designing a data pipeline with fault tolerance and error handling involves incorporating specific components and practices to ensure the reliability, resilience, and robustness of the system. Here are some key aspects to consider when designing such a system:
- Data Replication and Backup: Implementing mechanisms for replicating and backing up data across multiple nodes or regions to prevent data loss in case of hardware failures, network outages, or other disruptions. This can be achieved using distributed file systems like Hadoop Distributed File System (HDFS) or cloud-based storage services like Amazon S3, Azure Blob Storage, or Google Cloud Storage.
- Data Partitioning and Bucketing: Using techniques like partitioning and bucketing to distribute data across multiple nodes or shards for better performance, scalability, and fault tolerance. This can help ensure that even if one node or shard fails, the rest of the system remains operational.
- Retry Logic and Circuit Breakers: Implementing retry logic to automatically reprocess failed tasks or operations and circuit breakers to prevent cascading failures in case of a prolonged failure affecting multiple components. Tools like Apache Beam, Apache Flink, or Apache Spark provides built-in support for retries and error handling.
- Dead Letter Queues (DLQ): Using dead letter queues to temporarily store failed messages or records that could not be processed successfully. This enables data engineers to conduct further investigation, debugging, or manual intervention. Tools like Apache Kafka or Amazon SQS support DLQs for better error handling and fault tolerance.
- Monitoring and Alerting: Setting up monitoring and alerting mechanisms to track system performance, resource utilization, and error rates, as well as to notify relevant personnel in case of issues or disruptions. Tools like Prometheus, Grafana, or cloud-based monitoring services can be used for this purpose.
- Automated Testing and Continuous Integration (CI): Implementing automated testing and continuous integration pipelines using tools like Apache Beam’s runner model or Spark’s Structured Streaming to validate data quality, schema compatibility, and other aspects of the system as changes are introduced.
- Data Validation and Schema Evolution: Enforcing data validation and schema evolution best practices to ensure that incoming data meets specific constraints and requirements and adapting the system to handle incremental or backwards-compatible schema updates over time. Tools like Apache Avro, Apache Parquet, or cloud-based managed services can help enforce these best practices.
- Containerization and Orchestration: Using containerization technologies like Docker and orchestration tools like Apache Airflow or cloud-based managed services to manage the deployment, scaling, and failover of data pipeline components. This helps ensure that even if individual nodes or containers fail, the system can automatically recover and continue processing data with minimal disruption.
- Logging and Auditing: Implementing logging and auditing mechanisms to track data flow, transformations, and user activities throughout the data pipeline. This can help debug issues, monitor performance, and demonstrate compliance with regulatory requirements like GDPR or CCPA. Tools like Apache Kafka, Fluentd, or ELK stack (Elasticsearch, Logstash, Kibana) can be used for this purpose.
- Data Governance: Establishing data governance policies and best practices to ensure that data is handled securely, accurately, and ethically throughout the pipeline. This includes implementing role-based access control, encryption, anonymization, or pseudonymization techniques to protect sensitive information and comply with regulatory requirements.
Discuss your experience with distributed storage systems like HDFS, S3, or Google Cloud Storage. Mention specific use cases where these systems were helpful.
The response to this question should be drawn from your personal project experience. I will provide a high-level overview of the advantages and use cases of various distributed storage systems. This answer is intended to serve as a foundation to help you formulate your own response.
Hadoop Distributed File System (HDFS): HDFS is an open-source distributed file system designed for storing large volumes of data across a cluster of commodity hardware. It’s tightly integrated with the Apache Hadoop ecosystem, including tools like MapReduce, Spark, and Hive, making it an ideal choice for big data processing and analytics workloads. Use cases for HDFS include:
- Data Processing and Analytics: Organizations often use HDFS as a primary storage layer for large-scale batch processing and real-time stream processing applications that require high throughput, low latency, and fault tolerance.
- Log Aggregation: Many companies leverage HDFS to collect, store, and analyze log data from various sources, like web servers, application servers or network devices for monitoring, troubleshooting, and security purposes.
Amazon Simple Storage Service (S3): Amazon S3 is a cloud-based object storage service that offers high scalability, durability, and availability for storing and retrieving large volumes of data. It’s widely used in various industries for various applications, including:
- Cloud Data Lakes: Organizations often use S3 to create cloud-based data lakes for centralized data storage, processing, and analytics workloads. Tools like AWS Glue, Athena, or Redshift can be integrated with S3 to enable fast querying and BI applications.
- Content Delivery and Media Sharing: Companies use S3 for hosting static websites, sharing multimedia content, or delivering software updates and patches to end-users due to its high scalability, global availability, and low latency.
- Data Backup and Archiving: Many organizations rely on S3 for data backup and archiving purposes, leveraging it’s low-cost and long-term retention capabilities for infrequently accessed data or compliance requirements.
Google Cloud Storage (GCS): Google Cloud Storage is a cloud-based object storage service provided by Google Cloud Platform that offers high scalability, durability, and performance for storing and managing large volumes of unstructured data. GCS use cases include:
- Cloud Data Warehousing: Organizations often integrate GCS with tools like BigQuery, Dataflow, or Dataproc to build scalable cloud-based data warehouses, enabling real-time analytics and BI applications.
- Machine Learning and AI Workloads: Companies use GCS for storing large datasets used in machine learning and artificial intelligence workloads, as it integrates seamlessly with Google’s AI tools like TensorFlow or AutoML.
- Hybrid Cloud Storage: Organizations may leverage GCS as a secondary storage layer in hybrid cloud architectures, enabling data synchronization between on-premises HDFS clusters and the cloud for disaster recovery, backup, or migration purposes.
Explain the difference between a message queue and a publish-subscribe messaging model. When would you choose one over the other?
Message queues and publish-subscribe (pub-sub) messaging models are widely used strategies for decoupling components in distributed systems, each with distinct characteristics and specific use cases. Let’s explore each concept and their differences:
Message Queue: In a message queue model, producers send messages to a centralized queue, which is then consumed by one or more dedicated consumers. Each consumer processes the messages sequentially, and once processed, the messages are removed from the queue. Message queues can be configured with various settings like priority, expiration, and visibility timeout for better control over message processing.
Key characteristics of message queues include:
- Point-to-point communication: Messages are delivered to a specific consumer in the order they were received, ensuring a clear producer-to-consumer relationship.
- Exclusive access: Each message is processed by only one consumer, preventing duplicate processing and enabling better control over resource utilization.
- Ordering guarantees: Messages within a queue are typically processed in the order they were received, allowing for strict FIFO (first-in, first-out) semantics if required.
Publish-Subscribe Messaging Model: In a pub-sub model, producers publish messages to one or more topics, and subscribers register their interest in specific topics to receive the published messages. Unlike message queues, messages are delivered concurrently to all subscribers interested in a topic, enabling decoupling between publishers and multiple subscribers.
Key characteristics of pub-sub messaging model include:
- Many-to-many communication: Producers can send messages to one or more topics, while subscribers can register for one or more topics, creating a highly flexible and decoupled system.
- Concurrent delivery: Messages are delivered concurrently to all subscribers interested in a topic, allowing for better performance and scalability when handling large volumes of messages.
- Non-ordering semantics: In most pub-sub systems, messages aren’t guaranteed to be processed in the order they were published, making this model more suitable for event-driven architectures where strict ordering isn’t required.
How do you ensure data security and privacy in your data engineering projects? Describe specific tools or techniques used to address this challenge.
Ensuring data security and privacy in data engineering projects involves various tools, techniques, and best practices to protect sensitive information while allowing for data access, processing, and sharing as required by the organization’s policies and regulations. Some of these strategies include:
- Data Encryption: Data encryption is essential to secure data at rest and in transit. This can be achieved using methods like symmetric or asymmetric encryption algorithms and tools such as AES, RSA, or elliptic curve cryptography. Tools for encryption include Apache NiFi’s encryption processors, AWS KMS, Google Cloud KMS, or Azure Key Vault.
- Access Control: Implementing proper access control is critical to managing who can access and manipulate data within the system. Role-Based Access Control (RBAC) or Attribute-Based Access Control (ABAC) are common methods to define roles, permissions, user attributes, groups, and resources. Tools for implementing access control include Apache Ranger, AWS IAM, Google Cloud IAM, or Azure Active Directory.
- Data Anonymization and Pseudonymization: Techniques like data anonymization (removing direct identifiers) and pseudonymization (replacing direct identifiers with pseudonyms) help protect individual privacy in datasets while preserving their utility for analysis. Tools and libraries for data anonymization include the ARX Toolkit, PySyft, or TensorFlow Privacy.
- Data Masking: Data masking involves replacing sensitive information with non-sensitive alternatives to maintain data integrity without revealing sensitive details. This technique is useful when sharing data with third parties or in non-production environments like testing and development. Tools for data masking include Apache NiFi’s data masking processors, AWS Glue DataBrew, or Google Cloud Dataplex.
- Secure Communication: Securing communication channels between components in the system ensures that data is protected while being transferred. Techniques like using secure protocols (HTTPS, SFTP), implementing certificate-based authentication, and enforcing firewall rules help maintain secure communication. Tools for securing communication include NGINX, Apache HTTP Server, or HAProxy.
- Monitoring and Auditing: Continuously monitoring the system for security vulnerabilities and auditing user activities ensure that potential threats are detected early and addressed promptly. This can be achieved using tools like Prometheus, Grafana, ELK Stack, or AWS CloudTrail.
- Security Training and Awareness: Educating team members about data security best practices, common threats, and the importance of responsible data handling is essential to maintaining a secure environment. This includes providing training on phishing awareness, strong password creation, and multi-factor authentication.
- Incident Response Plan: Establishing an incident response plan outlines clear steps for identifying, containing, and resolving security incidents. This helps ensure the organization can react quickly and efficiently to potential threats while minimizing damage.
Describe your experience with workflow management systems (e.g., Apache Airflow, Luigi) for creating complex ETL pipelines.
Workflow management systems help data engineers create, manage, and monitor complex ETL (Extract, Transform, Load) pipelines by offering a unified interface for defining tasks and their dependencies, scheduling, monitoring, and error handling. Two popular workflow management systems are Apache Airflow and Luigi. Let’s explore their features and compare them:
Apache Airflow: Developed as an open-source platform by Airbnb, Airflow is a highly customizable workflow management system written in Python. It offers dynamic pipeline generation, task chaining, and parallelism to handle complex ETL pipelines. Key features include:
- Directed Acyclic Graphs (DAGs): Tasks are organized as directed acyclic graphs, where nodes represent tasks and edges define their dependencies and order of execution.
- Python-based DSL (Domain Specific Language): Airflow uses a Python-based DSL for defining workflows, allowing data engineers to leverage the full power of a general-purpose programming language for customization and flexibility.
- Rich User Interface: Airflow provides an intuitive web UI for visualizing workflows, monitoring their progress, and troubleshooting issues.
- Workers and Schedulers: Airflow utilizes distinct worker processes to execute tasks, while scheduler components monitor directed acyclic graphs (DAGs) and schedule task execution based on predefined schedules or triggers.
- Extensibility: Airflow allows for easy extensibility through plugins, operators, hooks, and sensors, enabling integration with a wide variety of data sources, tools, and services.
Luigi: Developed by Spotify as an open-source platform, Luigi is another workflow management system written in Python. It’s explicitly designed to manage complex batch-processing tasks, including ETL pipelines. Key features include:
- Task Classes: Workflows are defined as task classes with their dependencies specified using input/output files or targets.
- Python API: Luigi offers a simple Python API for defining workflows, making it easy for data engineers familiar with the language to learn and use.
- Command-Line Interface (CLI): Luigi provides a command-line interface for running and monitoring tasks, enabling better integration with other tools in the data pipeline.
- Task Scheduling: Luigi includes built-in support for scheduling and retrying failed tasks and parallelism through worker processes.
- Modular Design: Luigi supports modular design by allowing reusable task classes, enabling better code organization and maintenance.
Choosing between Airflow and Luigi depends on the specific needs of your project:
- Choose Airflow if you require advanced features like dynamic pipeline generation, customizable scheduling, or extensive plugin support.
- Choose Luigi for a more lightweight solution focused on managing complex batch processing.
Explain the concept of lazy evaluation and its importance in distributed processing frameworks like Spark or Flink.
Lazy evaluation is a programming design technique where an expression or function call’s computation is delayed until its result is actually needed, rather than evaluating it immediately when the expression is encountered. This approach can significantly improve performance, particularly in distributed processing frameworks like Apache Spark and Apache Flink, by postponing unnecessary computations and optimizing resource usage.
Let’s explore how lazy evaluation works and its importance in distributed processing frameworks:
How Lazy Evaluation Works: In lazy evaluation, an expression or function call is not evaluated until the result is explicitly requested(e.g., by calling a get() method on a generator or iterator). This allows for deferred computations that can be combined and optimized before execution.
Lazy Evaluation in Distributed Processing Frameworks: In Spark, Flink, and similar distributed processing frameworks, lazy evaluation is typically employed when defining transformations (e.g., map(),filter()) on data collections like RDDs (Resilient Distributed Datasets) or DataFrames. When a transformation is applied to the data collection, no actual computation takes place until an action (e.g., count(),collect()) is called.
The benefits of lazy evaluation in distributed processing frameworks include:
- Performance Optimization: By deferring computations, unnecessary operations can be avoided or combined with other transformations to improve overall performance. The system can analyze the entire pipeline and apply optimizations like task coalescing, data repartitioning, or operator fusion before executing any computation.
- Resource Efficiency: Delaying computations until needed allows for better resource management by minimizing memory consumption and CPU usage during the processing phase. This is particularly beneficial in distributed environments where resources can be limited or expensive.
- Abstraction: Lazy evaluation enables data engineers to define complex transformations without worrying about the underlying implementation details, making it easier to create and maintain ETL pipelines.
- Modularity: By decoupling transformation definitions from computation execution, lazy evaluation promotes modular design principles, enabling better code organization and reuse.
The lazy evaluation feature is explained in this blog post with an example using Pyspark.
Discuss your experience working with cloud infrastructure (AWS, GCP, Azure). Describe specific projects where you leveraged their services to build data solutions.
Discuss various platforms utilized for creating scalable, secure, and cost-effective data solutions. Discuss different industries such as healthcare, finance, retail, and technology for which these solutions have been developed.
Here are a few talking points: Healthcare Analytics Platform on AWS: The design and development of a cloud-based healthcare analytics platform using AWS services might include the following components:
- Amazon Elastic Compute Cloud (EC2) is used to provision and manage virtual servers to run custom analytics workflows.
- Amazon Simple Storage Service (S3) is a secure, durable object storage for large datasets and intermediate results.
- Amazon Kinesis Data Streams for real-time data ingestion from various sources like IoT devices, EHR systems, and mobile apps.
- Amazon Redshift for fast, scalable data warehousing to support complex analytics queries and reporting.
- AWS Lambda for serverless processing of batch and real-time datasets using custom Python scripts.
Data Science Platform on GCP: The Design and implementation of a cloud-based data science platform for a research organization using GCP services might include:
- Google Compute Engine (GCE) for provisioning virtual machines running various analytics workloads, including machine learning models.
- Google Cloud Storage (GCS) as durable object storage for storing datasets and model artifacts.
- Google Kubernetes Engine (GKE) to orchestrate containerized data processing tasks using tools like Apache Beam and TensorFlow.
- BigQuery ML for training and deploying machine learning models directly within the data warehouse, reducing time-to-insight.
- Cloud Dataproc for running distributed analytics jobs on Apache Spark and Apache Hive.
Financial Analytics Platform on Azure: The development of a cloud-based financial analytics platform using Azure services might include:
- Azure Virtual Machines for provisioning and managing virtual servers to run custom analytics workflows.
- Azure Blob Storage for secure, scalable object storage for storing large datasets and intermediate results.
- Azure Data Factory for orchestrating data pipelines with support for various connectors and transformations.
- Azure Synapse Analytics (formerly SQL DW) for fast, scalable data warehousing to support complex analytics queries and reporting.
- Azure Databricks for running distributed analytics tasks on Apache Spark.
How do you optimize SQL queries for performance? Mention specific strategies and tools used to profile and improve query execution time.
Optimizing SQL queries is crucial for improving database performance, reducing resource consumption, and ensuring timely delivery of business insights. Various strategies and tools can be employed to profile and improve query execution time. Here are some specific methods:
Query Rewriting: Analyze the query structure and rewrite it using alternative SQL syntax or techniques that can help the database optimizer generate a more efficient execution plan, such as:
- Filtering early in the query to reduce the amount of data processed downstream.
- Using
JOINstatements instead of subqueries when possible. - Utilizing
EXISTSandINclauses appropriately based on cardinality estimates. - Breaking complex queries into smaller, manageable parts using temporary tables or Common Table Expressions (CTEs).
Index Optimization: Identify missing indexes or underperforming ones that can benefit from redesign or restructuring:
- Creating single-column or multi-column indexes on frequently used filter columns.
- Analyzing the selectivity of indexed columns to ensure efficient use by the query optimizer.
- Implementing index-organized tables (IOT) for faster access to clustered data.
- Evaluating and fine-tuning existing indexes using tools like SQL Server’s Database Tuning Advisor or MySQL’s Slow Query Log.
Query Plan Analysis: Investigate the query execution plan generated by the database optimizer to identify bottlenecks or inefficiencies:
- Analyzing the number and types of operators, such as table scans, index seeks, hash joins, or sort operations.
- Identifying full table scans that can be replaced with more efficient indexed access methods.
- Examining data skew that might cause performance issues in parallel processing scenarios.
- Comparing the estimated vs. actual row counts to identify potential discrepancies leading to suboptimal execution plans.
Database Configuration: Adjust database settings and configurations to improve query performance:
- Allocating sufficient memory for query processing, such as increasing
sort_memory_sizein MySQL orquery_memory_grant_timeout_secin MSSQL. - Enabling query cache when appropriate to reduce the overhead of parsing and planning frequent queries.
- Configuring parallelism options like cost-based optimization for Oracle, maximum degree of parallelism for SQL Server, or max_parallel_workers_per_gather in PostgreSQL.
Profiling Tools: Leverage tools and utilities to profile query execution time, diagnose issues, and monitor performance:
- MySQL Slow Query Log for identifying long-running or resource-intensive queries.
- SQL Server Management Studio (SSMS) for analyzing actual query plans, query statistics, and wait types.
- Oracle Statspack or Enterprise Manager for capturing performance metrics and generating reports.
- PostgreSQL’s
explaincommand with ANALYZE option to gather detailed execution plan information.
These strategies, when applied thoughtfully and in conjunction with one another, can significantly improve SQL query performance, reduce resource usage, and help deliver actionable insights more efficiently.
Explain the difference between ACID properties and eventual consistency in distributed systems, and discuss scenarios when each is appropriate.
ACID (Atomicity, Consistency, Isolation, Durability) and eventual consistency are two different approaches to ensuring data integrity in distributed systems. They cater to distinct use cases based on the desired trade-offs between performance, availability, and data consistency.
ACID Properties: A distributed system exhibiting ACID properties provides strong consistency guarantees for transactions. It ensures that every transaction is processed reliably and consistently, making it appropriate for scenarios where immediate consistency and correctness are crucial:
- Atomicity: Ensures that a transaction is treated as a single unit of work, either succeeding entirely or failing completely without leaving the system in an inconsistent state.
- Consistency: Guarantees that every transaction adheres to all defined constraints and invariants, preserving integrity rules and data relationships.
- Isolation: Ensures that concurrent transactions do not interfere with each other, providing isolation levels (e.g., serializable, snapshot) that control the degree of interaction between them.
- Durability: Committed transactions are guaranteed to be stored persistently and will survive failures or restarts.
Eventual Consistency: Eventual consistency is an approach where distributed systems relax consistency guarantees in favour of availability and performance. This model allows for temporary inconsistencies between replicas, with the system eventually converging on a consistent state as updates propagate:
- Basis: Assumes that most updates are localized to small subsets of data, and changes will be propagated to other replicas over time based on network conditions and concurrent update rates.
- Relaxed Consistency: Permits temporary inconsistencies between replicas, allowing for higher availability, lower latency, and better scalability at the cost of immediate consistency.
- Conflict Resolution: Requires additional mechanisms to resolve data conflicts when updates overlap or collide, such as vector clocks, last-writer-wins, or custom merge functions.
Scenarios for ACID and Eventual Consistency:
- ACID: Use cases that require strong consistency guarantees, such as financial transactions, order processing, or data warehousing systems where maintaining correctness is paramount.
- Eventual Consistency: Applications with relaxed consistency requirements, such as social media feeds, chat applications, or content delivery networks (CDNs) where immediate consistency is not a primary concern.
It’s essential to understand that neither approach is inherently better than the other; they serve different purposes based on the application requirements and desired trade-offs between performance, availability, and data consistency.
Describe your experience with data warehousing solutions like Redshift, BigQuery, or Snowflake. Mention specific use cases where these systems were helpful.
Discuss your experience in designing, implementing, and optimizing data pipelines. Talk about using these systems and tools in different scenarios where they excel. Here are a few talking points:
Amazon Redshift: As a part of the Amazon Web Services (AWS) ecosystem, Redshift is a fully managed columnar-storage data warehouse service that integrates well with other AWS tools and services. It’s an excellent choice for organizations already invested in or looking to leverage AWS infrastructure for their analytics needs.
- Data Migration: Discuss a migration project in which data was transferred from a legacy on-premises data warehousing solution to Amazon Redshift. Highlight the improvements in query performance and maintenance costs resulting from utilizing the managed and elastic features of the service.
- Real-time Analytics: Discuss the design and implementation of a real-time analytics pipeline. The real-time data may originate from an IoT device. This discussion should focus on using Redshift Spectrum, Amazon Kinesis Data Firehose, and AWS Lambda to process and analyze streaming data in near real-time for predictive maintenance purposes.
Google BigQuery: As part of Google Cloud Platform (GCP), BigQuery is a fully managed, serverless, and scalable data warehouse solution that supports SQL-like queries on petabyte-scale datasets with minimal configuration or management overhead. It’s an ideal choice for organizations looking to process massive volumes of data with minimal infrastructure maintenance.
- Ad-hoc Analytics: Useful in implementing a flexible ad-hoc analytics platform, possibly for a marketing firm, enabling users to quickly and easily run complex queries on large datasets without worrying about underlying infrastructure or performance tuning.
- Data Integration: BigQuery’s federated data source capabilities help integrate data from multiple sources (e.g., Google Sheets, Cloud Storage, Cloud SQL), allowing users to analyze and report on consolidated data without needing ETL processes or data duplication.
Snowflake: A cloud-based, fully managed data warehousing solution that supports structured and semi-structured data processing with SQL-like queries. It’s an excellent choice for organizations seeking a flexible, feature-rich data warehousing solution that can scale to meet demanding analytical needs.
- Data Science: Can be used in a financial services firm to build a cloud-based analytics platform using Snowflake, enabling their data scientists and analysts to process large datasets alongside semi-structured data sources (e.g., JSON, Avro) for predictive modelling and analysis.
- Cross-platform Analytics: Can be used to design an analytics solution to integrate data from multiple cloud providers (AWS, GCP, Azure), allowing users to analyze their consolidated data without concerns around underlying infrastructure or data format limitations.
How do you ensure high availability and fault tolerance for a system that handles critical business processes? What components would you include to achieve this goal?
- Component Redundancy: Implement redundant components at various levels of the infrastructure stack, including hardware resources, software services, and networking equipment, to minimize single points of failure.
- Load Balancing: Use load balancers to distribute incoming traffic across multiple instances or servers, providing evenly balanced workloads and increased capacity during peak loads. Implement health checks and automatic failover mechanisms for load balancers to ensure seamless transitions in case of failures.
- Automated Failover: Implement automated failover systems that monitor the health and availability of critical components, triggering seamless transitions to standby or backup resources in case of failures. Consider using multi-region or multi-cloud architectures for added resilience.
- Data Replication: Maintain multiple copies of crucial data across different geographical locations or availability zones, employing synchronous or asynchronous replication methods based on desired consistency levels and performance requirements.
- Disaster Recovery: Design a comprehensive disaster recovery plan that includes regular backups, offsite storage, and documented recovery procedures for various failure scenarios, such as data centre outages or regional disruptions.
- Monitoring and Alerting: Establish robust monitoring and alerting systems to track the performance, availability, and health of critical components in real-time, proactively identifying and addressing potential issues before they impact users.
- Testing: Regularly test HA and fault tolerance measures to validate their effectiveness and identify areas for improvement or optimization. Schedule regular drills or simulations to ensure that disaster recovery plans are up-to-date and effective.
- Chaos Engineering: Intentionally introduce controlled failures into the system to assess its resilience and ability to recover from disruptions, uncovering weaknesses and improving overall fault tolerance in a proactive manner.
- Continuous Integration and Deployment (CI/CD): Implement CI/CD pipelines that allow for automated testing, deployment, and rollback of application updates, ensuring minimal downtime and reducing the risk of human errors during maintenance or upgrade processes.
- Virtualization and Containerization: Leverage virtualization or containerization technologies to abstract applications from underlying infrastructure, allowing for flexible resource allocation, rapid scaling, and easy migration across different environments.
By incorporating these principles and techniques, you can build a highly available and fault-tolerant system capable of handling critical business processes with minimal disruptions, ensuring maximum uptime, and maintaining data integrity.
Describe your experience with version control systems (e.g., Git). Explain how you’ve used them in collaborative projects, and mention specific workflows or practices followed.
Git-based workflows can be utilized to manage code changes, maintain development history, and facilitate collaboration among team members:
Git Workflows:
- Centralized Workflow: In smaller teams or for simpler projects, A centralized workflow can be used, where developers clone a central repository, make changes locally and push those changes back to the central repository.
- Feature Branch Workflow: A feature branch workflow can be implemented for larger projects with multiple features being developed simultaneously. In this approach, each developer creates a dedicated branch for their work, which is later merged into the main or development branches after a review. This approach helps isolate changes and simplifies conflict resolution.
- GitFlow Workflow: When managing complex release cycles with multiple simultaneous releases, hotfixes, and development branches, follow the GitFlow workflow, which provides a well-defined structure for maintaining and merging long-lived branches representing various stages of the software development lifecycle.
- GitHub Flow Workflow: For continuous integration and deployment scenarios where code is frequently released to production, use the GitHub flow workflow, which emphasizes quick iterations, small pull requests, and automated testing before merging changes into the main branch.
Collaborative Practices: In collaborative projects, several practices are implemented to ensure efficient and effective use of Git:
- Clear Commit Messages: Encouraging developers to write clear, concise and descriptive commit messages that explain the purpose and context of each change, making it easier for other team members to understand and review code.
- Frequent Commits: Promoting frequent commits to keep changes manageable, reduce merge conflicts, and maintain a well-documented development history.
- Pull Requests (PRs): Leveraging pull requests as a platform for code reviews, discussions, and collaboration among team members, ensuring high code quality and enabling knowledge sharing.
- Automated Testing: Integrating automated testing into the Git workflow to identify issues and regressions early in the development cycle, providing faster feedback loops and reducing manual testing efforts.
- Continuous Integration (CI): Implementing CI pipelines that automatically build, test, and deploy code changes after they are merged into the main branch, ensuring a consistent and reliable development environment for all team members.
- Git Hooks: Utilizing Git hooks to enforce quality gates, such as linting, formatting, or security scanning before allowing code commits, ensuring high code standards and consistency across projects.
These questions cover various aspects of data engineering and are designed to assess your understanding of fundamental concepts, problem-solving skills, and practical experiences. Be prepared to answer both theoretical and practical questions related to the tools, technologies, and methodologies used in data engineering.